ByteDance
int64 check a + b > c
Tips:
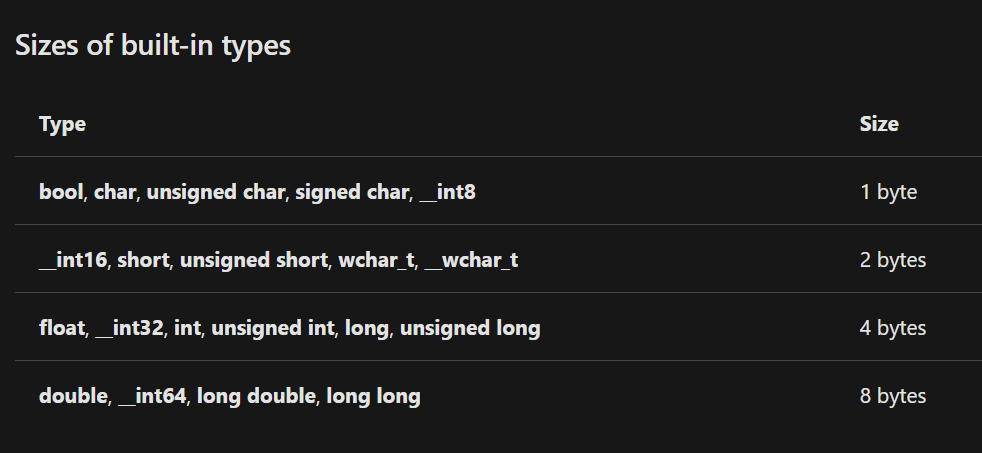
溢出 overflow 主要有两种:
- a, b 同号, c 与 a, b 同号, 转化成 a > c - b
- a, b 同号, c 与 a, b 异号: 负数 + 负数 > 正数 return False 正数 + 正数 > 负数 return True
- a, b 异号,直接判断 不会溢出
bool check(int A, int B, int C)
{
if ((A >= 0 && B <= 0>) || (A <= 0 && B >= 0>)) // A 和 B 异号
{
if ( A + B > C)
{
return true;
}
return false;
}
else// A 和 B 同号
{
if ((A > 0 && C >= 0) || (A < 0 && C <= 0>>))// A 和 C 同号
{
if (A > C - B)
{
return true;
}
return false;
}
else // A 与 C 异号
{
if ( A > 0)
{
return true;
}
return false;
}
}
}
Heap Data Structure
It must be full binary tree!!! That is why it can preserve O(logN) complexity.
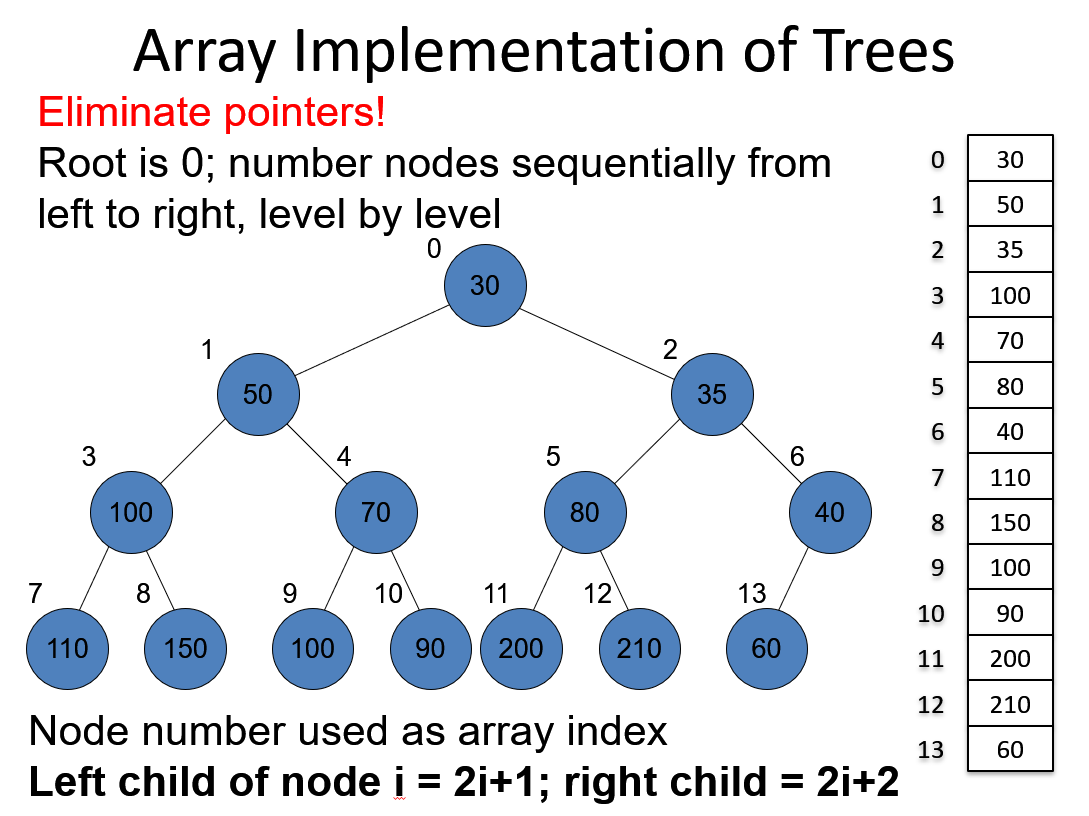
2i+1, and 2i+2 for left child and right child; (i « 1) + 1 or (i « 1) + 2 parent = (j - 1) » 2
Heap provides a very efficient data structure for implementing priority queue !!
最大堆,最小堆!!
Binary Search Tree
Not guaranteed with a height of logN because BST is not always a balanced tree.
Nvidia
XOR 异或 a ^ b
1、交换律 a^b = b^a
2、结合律(即(a^b)^c == a^(b^c))
3、对于任何数x,都有x^x=0,x^0=x
4、自反性 A XOR B XOR B = A xor 0 = A 最重要的特性,自反性
A XOR B XOR B = A,即对给定的数A,用同样的运算因子(B)作两次异或运算后仍得到A本身。
example: 交换a,b,c 三个数
a = a^b;
b = b^a;
a = a^b;
1-1000放在含有1001个元素的数组中,只有唯一的一个元素值重复,其它均只出现 一次。每个数组元素只能访问一次,设计一个算法,将它找出来;不用辅助存储空 间,能否设计一个算法实现?
将所有的数全部异或,得到的结果与1^2^3^…^1000的结果进行异或,得到的结果就是重复数
& 按位与
两位同时为“1”,结果才为“1”,否则为0 负数按补码形式参加按位与运算。
“与运算”的特殊用途:
(1)清零如果想将一个单元清零,即使其全部二进制位为0,只要与一个各位都为零的数值相与,结果为零。
(2)取一个数中指定位
方法:找一个数,对应X要取的位,该数的对应位为1,其余位为零,此数与X进行“与运算”可以得到X中的指定位。
例:设X=10101110,
取X的低4位,用 X & 0000 1111 = 0000 1110 即可得到;
还可用来取X的2、4、6位。
求非负二进制数中1的个数,按位与 n&n-1
int hammingWeight(uint32_t n)
{
int res = 0;
while(n)
{
n &= n - 1;
++ res;
}
return res;
}
| 按位或
参加运算的两个对象,按二进制位进行“或”运算。
运算规则:0|0=0; 0|1=1; 1|0=1; 1|1=1; 参加运算的两个对象只要有一个为1,其值为1 例如:3|5 即 0000 0011 | 0000 0101 = 0000 0111 因此,3|5的值得7。
另,负数按补码形式参加按位或运算
“或运算”特殊作用:
(1)常用来对一个数据的某些位置1
方法:找到一个数,对应X要置1的位,该数的对应位为1,其余位为零。此数与X相或可使X中的某些位置1。
| 例:将X=10100000的低4位置1 ,用 X | 0000 1111 = 1010 1111即可得到。 |
经典面试题
面试核心思想
- different
- XOR, 按位与,按位或
- allreduce: tree, butterfly
- 位图法
- 缓存之间的交换
- 精度损失
- 分块,分row and column
- 分block计算
- 矩阵幂快速运算,把一些计算转化成矩阵运算
面试题目
1)介绍自己的项目我就说了CUDA的研发经历是偏研究性质的。
2)不用中间变量,交换a,b,c三个数因为之前,有听室友提过。后来看了一下网上的说法,算是有准备。这就相当于两次两个数的交换,我先说了有加减的方法,但是说这有缺点会越界。然后就提到用异或操作,并描述了具体过程。
different or XOR
y = x + y
x = y - x
y = y - x
x = x^y
y = y^x
x = x^y
3)2n个数,有n个处理器,如何求和。基础题。归约就可以。然后就是10n的情况,我说的是先收到2n再做归约。进一步问了2n个数的时候归约求和的话,走多少步。1+logn。多少个加操作。其实永远都是2n-1当时傻了一下还按归约的树状结构推了一下。
allreduce 树状结构 logN
4)反正也是基础题:描述线程和进程。
线程是系统指令执行的最小单位,有自己独立的寄存器。但是共享代码区域。
进程是系统资源分配和执行的最小单位,不同进程之间的独立的。进程可以分配多个线程。
5)说说拿到串行以后的优化思路。
- 能否分成并行运行的组块。如果数据集过大,可以考虑,多个streams异步计算,从而多个kernel function。
- 能否减少串行
- 使用shared memory
- 通过选择block大小来提高占有率
- 聚集对global memeory 的访问
- 减少warp的分支,最好对齐
- 减少对 shared memory 的 bank-conflicts. 对齐
- 减少CPU-GPU的数据传输
6)主要是多处理器,带宽,延时和复杂度的问题,都是计算。还有计算密集,数据密集的判断。
Latency + communication complexity/bandwidth + size of datasets* computation time per data.
7)向量点乘,坐标表示。这个好写
8)向量叉乘,坐标表示。忘了,只记得用sin的表示了。考官表示理解,问我是向量还是标量,我说是向量。就继续了。
9)向量旋转¢角度。记得三角函数展开,就现推了,他提示我用极坐标带换一下,顺利推出来了。
10)计算一个非负整形二进制表示中一的个数。写代码。我用位操作写的。也算是基础题吧
int count = 0;
while(n)
{
n &= (n-1);
count ++;
}
11)用一行代码判断,一个非负整形是否是二的指数次方。有点难。我只好说就是2 4 8….按位与再或一下。他提示了我很多,最后不算是我自己想出来的了吧。就是减一的结果和原先的做按位与,判断是否为零。
int n = 2;
if (n&(n-1) == 0) return true;
12)面试题 有个单链表,只知道跑指针p,需要删除该节点,怎么办?写代码的。判断是否是尾以后,复制后面的节点,然后删除后面的。没什么难的
13)一个任务可分成n个不可再分的子任务[1~n],第i个任务执行i秒。顺序要多少秒? n(n+1)/2无限个处理器要多少秒?n希望处理器空闲时间最少,如何分配任务,空闲多少时间?就是对折,分奇偶讨论。奇数,1~(n-1)对折,用n 秒,空闲0秒,偶数,1~n对折,用n+1秒,空闲0秒,1~n-1对折,用n秒,空闲(n-1)/2秒。我考虑的是用时不变,所以说的是1、3情况。二是补充的。
14)CUDA同步函数,__sycnthreads()(好像没拼错)的作用。如何实现块间同步。因为之前有试过,我就说用global里面建锁就可以,加上原子操作。还把以前遇到的问题也和他讨论了。
Atomic Functions: An atomic function performs a read-modify-write atomic operation on one 32-bit or 64-bit word residing in global or shared memory. For example, atomicAdd() reads a word at some address in global or shared memory, adds a number to it, and writes the result back to the same address. The operation is atomic in the sense that it is guaranteed to be performed without interference from other threads.
15)C的链表为什么在GPU里不合适
因为C的链表是非连续的内存,而GPU大多做的是矩阵的运算,需要的是对连续内存的快速访问,而这里面就牵扯到DRAM的burst机制,如果能够将线程访问的数据是连续的,通过burst机制能够一次性将数据导入。最好能填满burst带宽 Memory references are coalesced into sequence of memory transactions
16)local memory,他先介绍了一下概念。然后说题目:每个线程搜索一个节点数不超过32的树,并开local memory作标记,有孩子结点的就记1,没有就记0。发现瓶颈在记录local memory上,带宽上限了。怎么优化?
17)非负整型排序好的数组A,B来记录每个不同的数第一次在A中出现的位置。写代码CUDA实现。
用原子操作: atomicMin(); no interference with other threads.
18)一个非负整型数组。一个数出现奇数次,其它出现偶数次。比如11232。如何找出出现奇数次的数。分析复杂度。我给的是用桶计数,建桶的方法就是哈希。时间复杂度n,空间有点大看哈希的策略。他提示的方法是异或。a^a=0; 0^a=a; a^b=b^a。全部遍历一遍就好。然后是GPU对应优化和分析。纠正了我一些理解错误,很nice。
19)然后问硬件上一个小问题,我没有啥经验,问题好像是CPU cache有 4 megabytes, 3 mega, 8 mega, using which cache is more efficiently?我说8 mega,因为transfer和process ratio更优(根据自我感觉)
1) MAP 和 MLE 的 区别 MLE:最大似然概率,对P(x|θ) 进行 计算,使得P最大的θ; MAP: 最大后验估计,对 P(θ|X) 进行计算,使得P最大的θ;
2) 样本比较少的时候,怎么让分类效果更好
数据层面:数据增广,对一个数据做休整,产生更多的样本; 合成数据
模型方面:正则化;k交叉验证;选择合适的模型;
3) 一个大int数组,所有数都在0-999之间,快速排序方法
位图法:按位或放置1在特定的位置,按位与判断某个数是不是已经出现过。
23) 一个长方形板子,挖了一个圆形的筒,求一种切分方法,恰好将面积等分 24) C++ override 和 overload
overload:重载实现不同的功能函数,比较表示方法一样,参数不一样,具体的指令也就不一样。 override:重写:指的是派生类的函数屏蔽了与其同名的基类函数; (1)如果派生类的函数与基类的函数同名,但是参数不同。此时,不论有无virtual关键字,基类的函数将被隐藏(注意别与重载混淆)。 (2)如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有virtual关键字。此时,基类的函数被隐藏(注意别与覆盖混淆)
25) imbalance dataset 的处理方法 26) reverse sequence of value: two pointers 27) reverse nth element from the end 28) 正则化方法:L1, L2 29) 2d array 根据 column进行操作:coalesing 和 warping的互相协调 30) warp的分支: 是同一个warp里面执行不同的指令
31)为什么推荐一维数组?
因为二维数组对应的每一行是不同的缓冲区,不是连续的,对应到GPU里面也是的。这样就不利于线程对DRAM burst 模式,也就是不能同时访问连续的内存区域。coalescing. 32) 为什么kernel functions 一定返回的是void?
因为如果不强制void,就会涉及到CPU里面一样的函数的return调用,这样就需要runtime stack去储存返回值的地址等等数据,这样对gpu是不高效的。应该直接对地址进行操作,所以就可以直接传入指针,对特定的地址进行操作,而不需要返回任何的值,也就是void。
Function call mechanism will impact performance A little time needed for function call/return Memory also required for stack; implications on recursion In a multi-threaded program, each thread has its own runtime stack, introducing some complexity