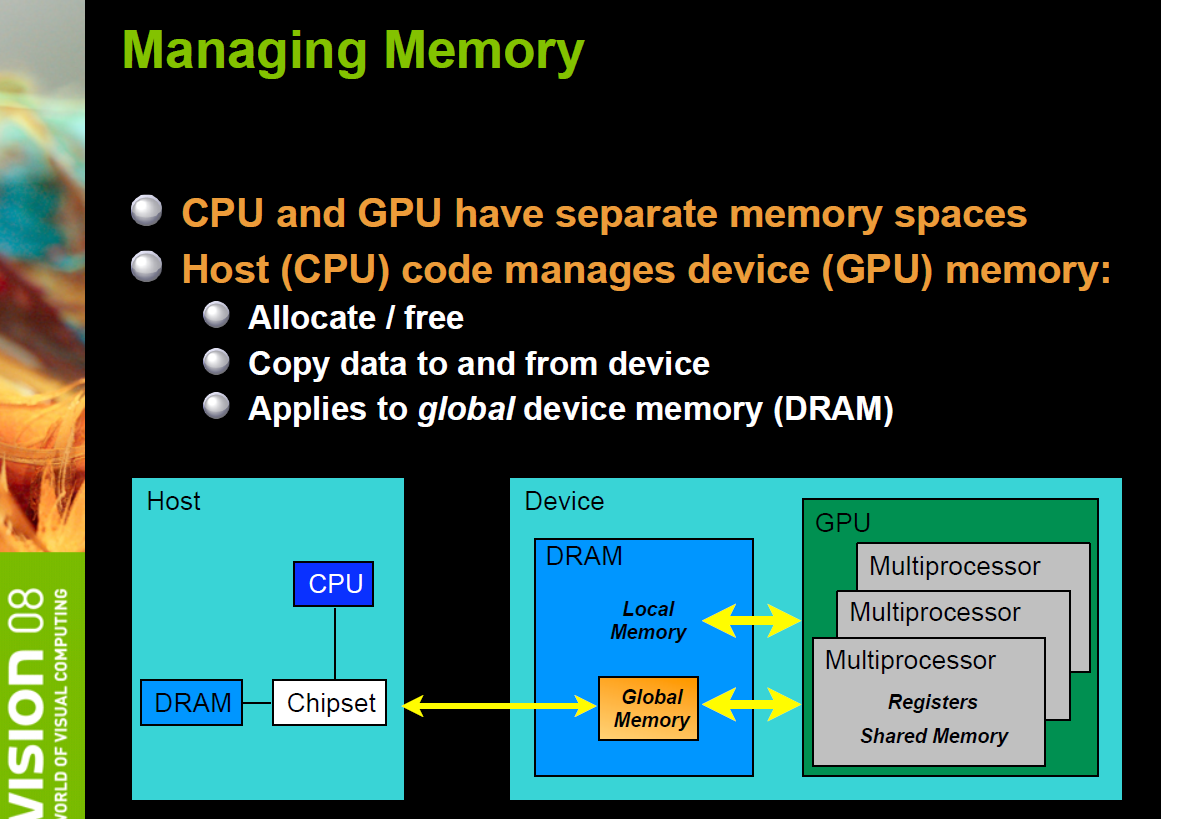
CUDA: host: CPU and its memory, host: GPU and its memory ; codes run on the host can manage memory on both the host and the device, and also launches kernels which are functions executed on the CUDA
CUDA cores: are parallel processors similar to a processor in a computer, which may be dual or quad-core processor
- Interactive Session: qsub -I -X -q coc-ice -l nodes=2:ppn=4:gpus:2:exclusive_process, walltime =01:00:00, pmem=2gb
- module load gcc/5.3.0 cuda/9.1
- nvcc vector_add.cu -o v_add
- ./v_add
从另一个视角来看上图,在CPU芯片中,运算单元(ALU)所占的比例较小,CPU中更多的硅片被用来制作控制单元和缓存,以完成复杂的逻辑;而GPU的运算单元使用的硅片面积比例要大于CPU,以完成高强度的计算。因此CPU的侧重点在于逻辑控制,而GPU的侧重点在于计算
目前的GPU限制一个线程块中,最多可以安排1024个线程。
一个线程块用多少线程,以及一个线程网格用多少线程块,是程序员可以自由安排的。由于32个相邻的线程会组成一个线程束(Thread Warp),而一个线程束中的线程会运行同样的指令。因此一般线程块中线程的数量被安排为32的倍数,选用256是比较合适的。
Kernels:
内核函数是CUDA 每个线程 执行的函数。CUDA使用扩展的C语言编写内核函数,关键字为global。内核函数返回值只能是void。
Restrictions
- Cannot access host memory
- Must have void return type
- No variable number of arguments (“varargs”)
- Not recursive
- No static variables
Function arguments automatically copied from host to device

由于GPU中的每个线程都会执行相同的VecAdd函数,因此不同的线程需要使用自己独有的ID来区分彼此,来获取不同的数据。这就是SIMT的概念,即“相同指令,不同线程”。
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[j][i] = A[j][i] + B[j][i];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
在内核函数中,i代表x方向上的ID,j代表y方向上的ID。blockDim代表当前线程块的尺寸。从程序中可以看到,x方向为行方向,y方向为列方向
Atomic Operations
其他thread不能访问同一块地址, 32 bits or 64 bits, global memory or

transferring data is the bottleneck
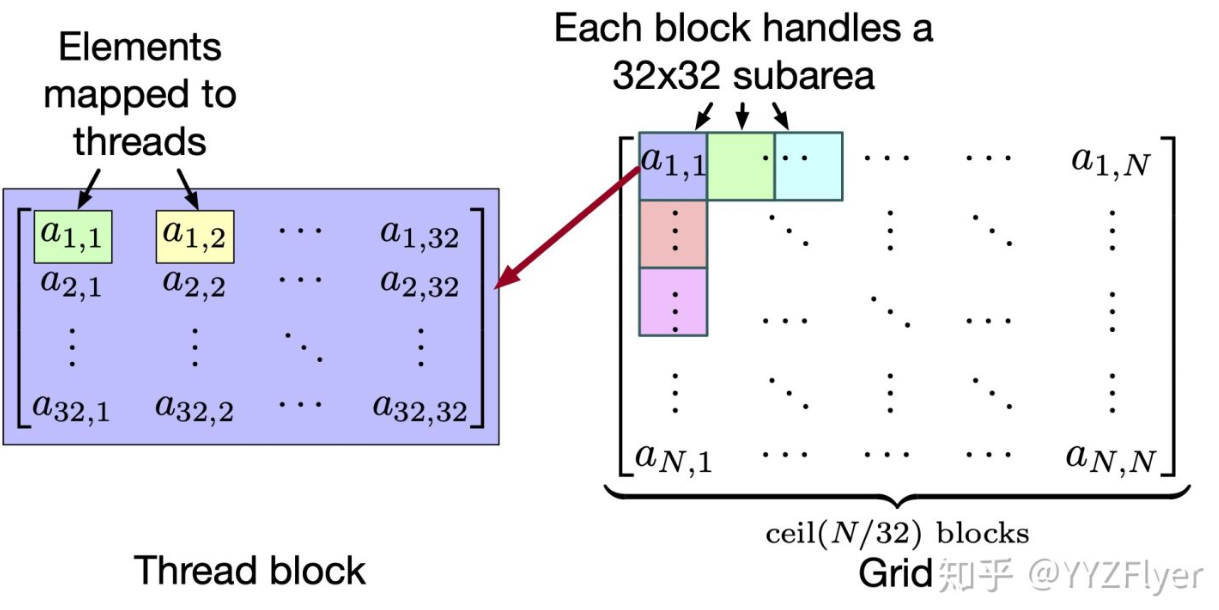
«<grid_size, block_size»>: grid_size = one grid contains how many blocks, block_size = one block contains how many threads. One kernel function only has one grid.
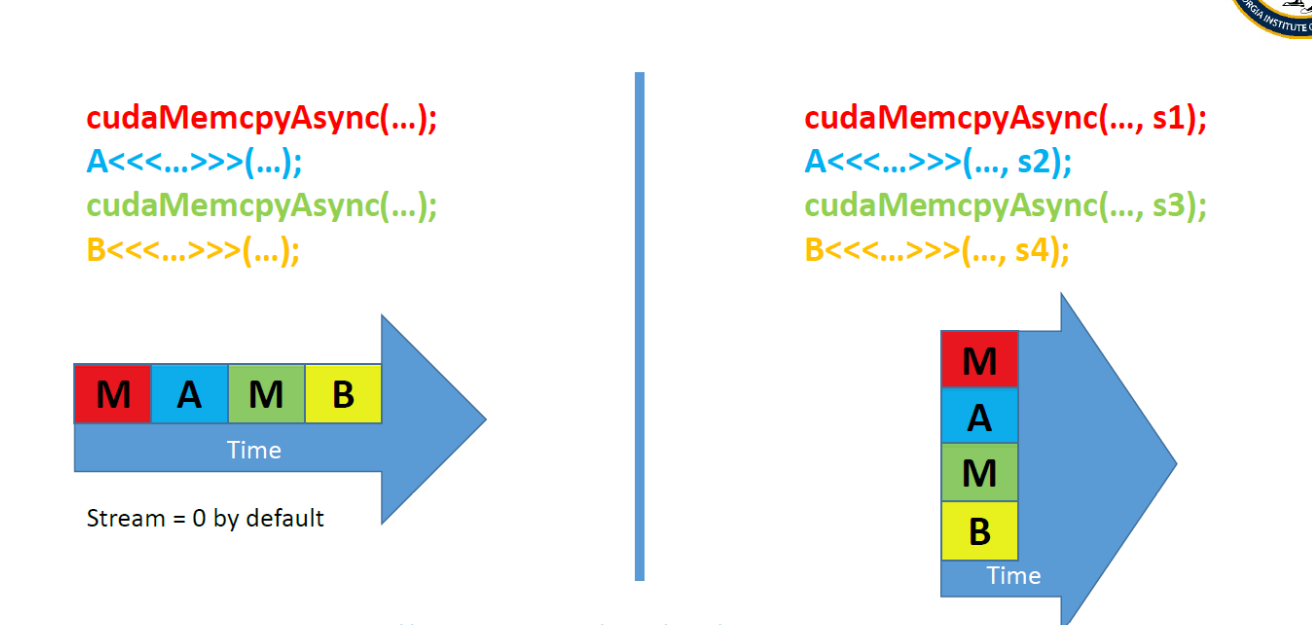
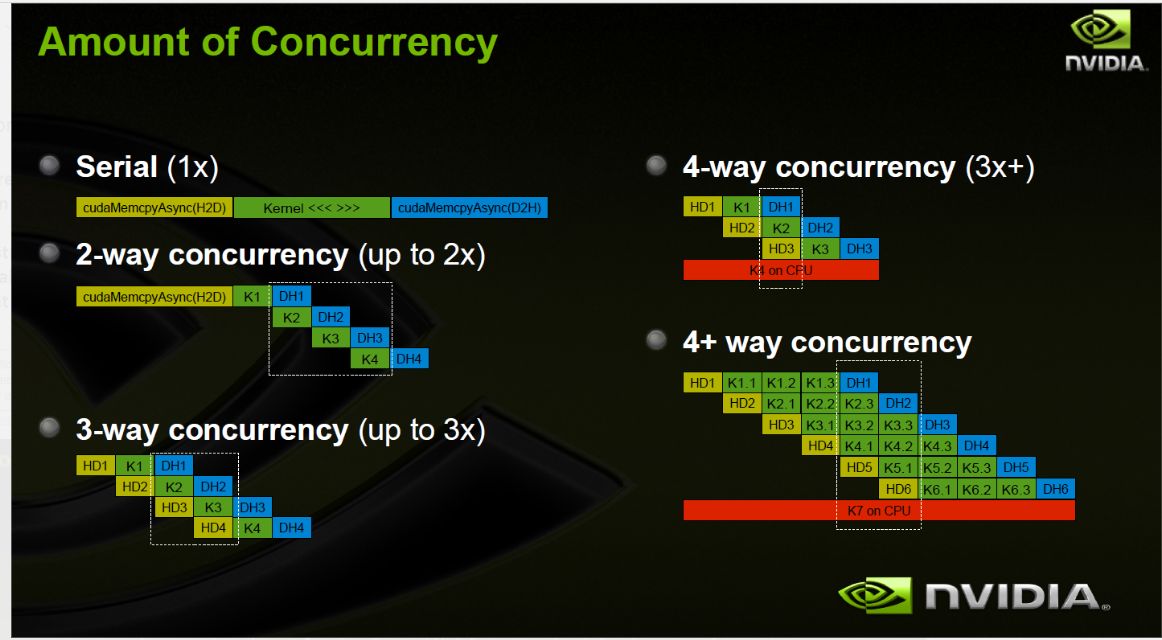
CUDA STREAMS
stream: a sequence of operations that executes in order on the GPU (memory transfers, kernels)

Requirement for concurrency:
默认来说:default就是stream 0, 也就是一个stream,没有concurrency, 那么每一个CUDA operation 之后都会有一个 cudaDeviceSynchronize()

在每个方向上只能有一个Memcpy, 因为PCIE的限制,也就是从host到device,从device到host;


kernel_name«<gridSize,blockSize,sharedMemorySize,stream»>(argument list)
Example:
- «<1,256»> ```c++ global void vector_add(float *out, float *a, float *b, int n) { int index = threadIdx.x; int stride = blockDim.x; for(int i = index; i < n; i += stride){ out[i] = a[i] + b[i]; } }

2. **<<<grid_size,block_size>>>**
```c++
__global__ void vector_add(float *out, float *a, float *b, int n) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
// Handling arbitrary vector size
if (tid < n){
out[tid] = a[tid] + b[tid];
}
}
int block_size = 256;
int grid_size = ((N + block_size) / block_size);
vector_add<<<grid_size,block_size>>>(d_out, d_a, d_b, N);

CUDA GPUs have several parallel processors called Streaming Multiprocessors or SMs. Each SM consists of multiple parallel processors and can run multiple concurrent thread blocks.
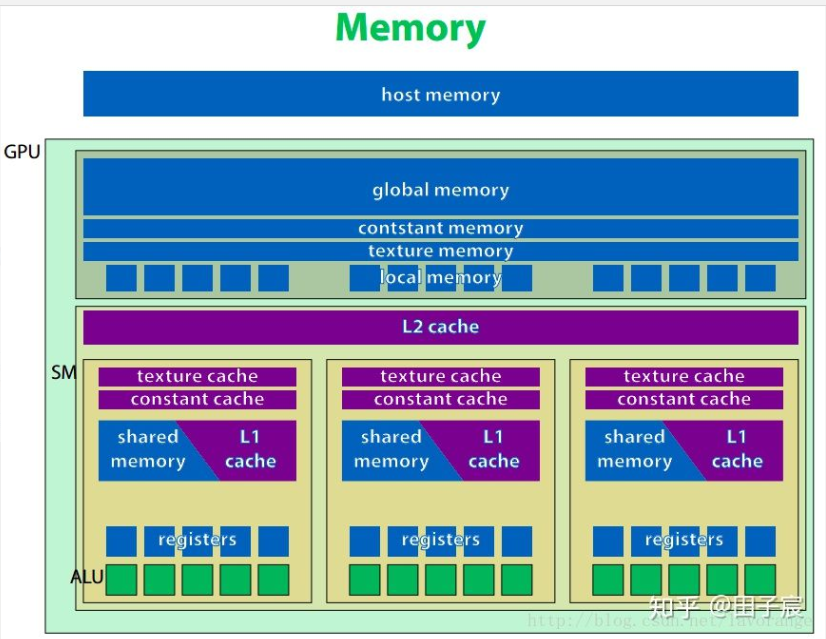
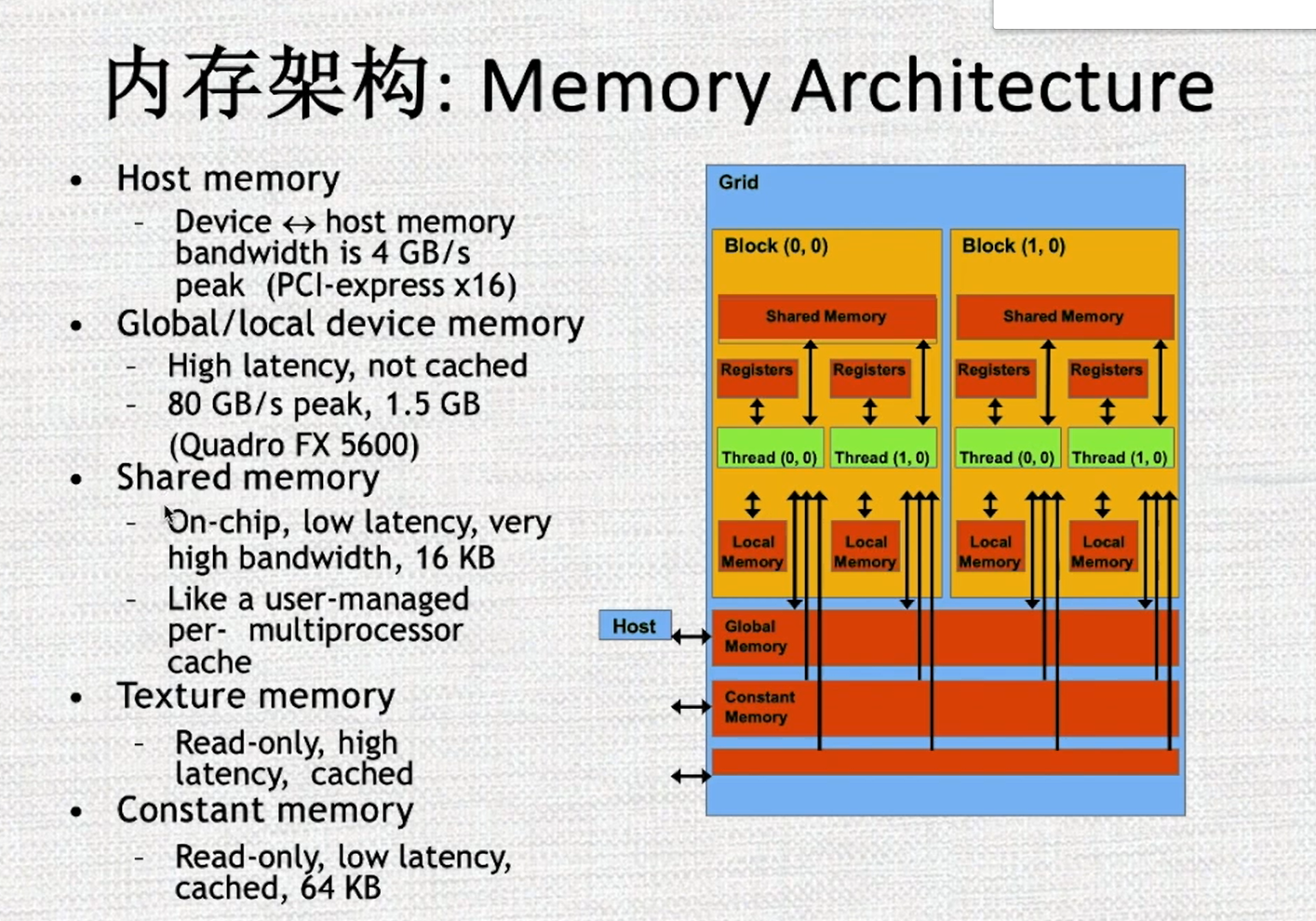
内存层级
同CPU一样,GPU也有不同层级的内存。越靠近核心的内存速度越快,但容量越小;反之,越远离核心的内存速度越慢,但容量较大。
GPU存储用DRAM 电容存储,比较慢,需要不断刷新,保持一段时间
Host 与 GPU 之间通过 PCI-E总线连接,交换数据,速度就是PCI-E总线的速度
-
全局内存(global memory) 、常量内存(constant memory)、纹理内存(texture memory)、本地内存(local memory)。都位于GPU板上,但不在片内。因此速度相对片内内存较慢。
常量内存和纹理内存对于GPU来说是只读的。
- GPU上有 L2 cache和 L1 cahce。其中L2 cache为所有流处理器簇(SM)共享,而L1 cache为每个SM内部共享。这里的cache和CPU的cache一样,程序员无法对cache显式操纵。
- 纹理缓存和常量缓存在SM内部共享,在早期1.x计算能力的时代,这两种缓存是片上唯一的缓存,十分宝贵。而当Fermi架构出现后,普通的全局内存也具有了缓存,因此就不那么突出了。
- 共享内存(shared memory, SMEM) 具有和L1缓存同样的速度,且可以被程序员显式操纵,因此经常被用作存放一些需要反复使用的数据。共享内存只能在SM内共享,且对于CUDA编程模型来说,即使线程块被调度到了同一个SM内也无法互相访问。
-
GPU的寄存器(registers) 和CPU不一样,其空间非常巨大,以至于可以为每一个线程分配一块独立的寄存器空间。因此,不像CPU那样切换进程时需要保存上下文,GPU只需要修改一下寄存器空间的指针即可继续运行。所以巨大的寄存器空间,使得GPU上线程切换成为了一个几乎无消耗的操作。
不过有一点需要注意,寄存器的空间不是无限大的。如果线程数过多,或一个线程使用的寄存器数量太多,多出来的数据会被保存到缓慢的本地内存上,影响程序速度,需要注意。
- 寄存器和本地内存绑定到了每个线程,其他线程无法访问
-
同一个线程块内的线程,可以访问同一块共享内存。注意,即使两个线程块被调度到了同一个SM上,他们的共享内存也是隔离开的,不能互相访问。
- 网格中的所有线程都可以自由读写全局内存。
- 常量内存和纹理内存只能被CPU端修改,GPU内的线程只能读取数据。
解决 SIMD single instruction multiple datasets 问题 异构指的的CPU + GPU , 中间是 kener functions
除了CPU/GPU交错执行代码的方式外,还可以通过使用事件(event)和流(stream)等方式,让CPU/GPU并行工作,提升整体的效率
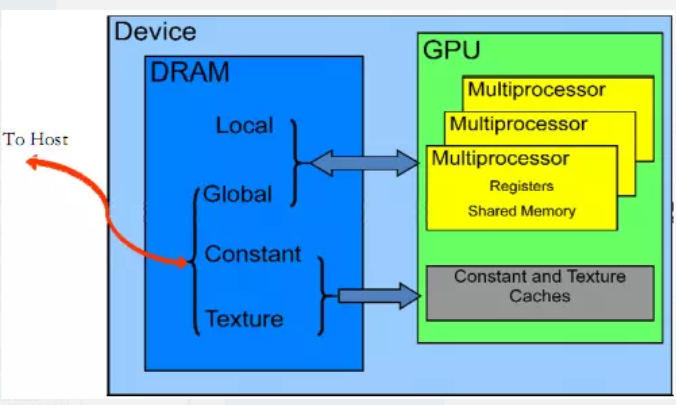
GPU 存储器
- 每个线程都有一个私有的本地存储器。
- 每个线程块都有一个共享存储器,该存储器对于块内的所有线程都是可见的,并且与块具有相同的生命周期。
- 所有线程都可访问相同的全局存储器。
- 此外还有两个只读的存储器空间,可由所有线程访问,这两个空间是常量存储器空间和纹理存储器空间。全局、固定和纹理存储器空间经过优化,适于不同的存储器用途。纹理存储器也为某些特殊的数据格式提供了不同的寻址模式以及数据过滤,方便Host对流数据的快速存取
共享内存 关键字:
__shared__ float cache[10]
线程块中的每个线程都共享这块内存,但线程却无法看到也不能修改其他线程块的变量副本。这样使得一个线程块中的多个线程能够在计算上通信和协作。 对于GPU上启动的每个线程块,CUDA C编译器都将创建该共享变量的一个副本
常量内存:
__constant__ float s[10]
– > 减少内存请求和带宽 NVIDIA硬件提供了64KB的常量内存。不再需要cudaMalloc()或者cudaFree(),而是在编译时,静态地分配空间 性能提升的原因:对常量内存的单次读操作可以广播到其他的“邻近”线程。这将节约15次读取操作(半个线程束);常量内存的数据将缓存起来,因此对相同地址的连续读操作将不会产生额外的内存通信量
纹理内存:
减少对内存请求并且提供高效的内存带宽。 只读内存。缓存在GPU上,内存访问模式里面有大量空间局部性(不是CPU存储局部性)而设计的。多个线程之间读取的位置很接近的时候。
texture<float> texConst;
需要通过cudaBindTexture()将这些变量绑定到内存缓存区。这相当于告诉CUDA运行时两件事:
- 我们希望将指定的缓冲区作为纹理来使用;
- 我们希望将纹理引用作为纹理的“名字”
- cudaUnbindTexture(texConst);
Pinned page memory: 锁页内存
(只能以异步的方式进行复制)– > 不会对内存分页,不会被内存消除掉,驻留在物理内存里面。连续的物理地址,而不会被破坏,安全访问这个物理地址 好处可以通过物理地址,进行 直接内存访问 (DMA) 来 进行 GPU和主机之间复制数据。 坏处:固定内存,失去虚拟内存的所有功能,系统将更快的耗尽内存.
原子性:
如果操作的执行过程不能分解为更小的部分, 我们将满足这种条件限制的操作称作为原子操作.
分段和分页:
虚拟内存 映射 到 物理内存上; 分页就是使得程序换入换出呈现粒度,也就是以某一页作为单位 (代码和数据,那些用不到的部分),解决内存使用率低下的问题.利用了空间局部性.
弗林分类法
- SIMDsingle instruction stream, multiple data stream computing. matrix operations. Multiple ALUs in data path. Single Control Unit.
- MIMD: multiple instruction stream, multiple data stream parallel computing. OpenMP (shared memory), MPI (message passing)
- SISD
- MISD
GPU 计算能力
体现GPU计算能力的两个重要特征:1)CUDA核的个数;2)存储器大小。
描述GPU性能的两个重要指标: :1)计算性能峰值;2)存储器带宽。(单位时间内存储器所存取的信息量,Bytes/s)
dim3 数据结构
dim3是基于uint3定义的矢量类型,相当于由3个unsigned int型组成的结构体。uint3类型有三个数据成员unsigned int x; unsigned int y; unsigned int z;
threadID=threadIdx.x+threadIdx.yblockDim.x threadID=threadIdx.x+threadIdx.yblockDim.x+threadIdx.zblockDim.xblockDim.y。
常用的GPU 内存 函数
cudaError_t cudaMalloc(void ** devptr, size_t size);
注意事项:
- 可以将cudaMalloc()分配的指针传递给在设备上执行的函数;
- 可以在设备代码中使用cudaMalloc()分配的指针进行设备内存读写操作;
- 可以将cudaMalloc()分配的指针传递给在主机上执行的函数;
- 不可以在主机代码中使用cudaMalloc()分配的指针进行主机内存读写操作(即不能进行解引用)
cudaError_t cudaMemcpy (void *dst, const void *src, size_t count, cudaMemcpyKind kind) 同步处理,输出在缓冲区; cudaMemcpyAsync()
cudaError_t cudaFree ( void* devPtr )。
常用线程操作函数: __syncthreads()
使用事件来测量性能
cudaEvent_t start, stop;
cudaEventCreate( &start );
cudaEventCreate( &stop );
cudaEventRecord( start, 0 );
//do something
cudaEventRecord( stop, 0 );
float elapsedTime;
cudaEventElapsedTime( &elapsedTime,start, stop );
cudaEventDestroy( start );
cudaEventDestroy( stop );
流 Stream
- 声明与创建:声明cudaStream_t stream;,创建cudaSteamCreate(&stream);。
- cudaMemcpyAsync():前面在cudaMemcpy()中提到过,这是一个以异步方式执行的函数。在调用cudaMemcpyAsync()时,只是放置一个请求,表示在流中执行一次内存复制操作,这个流是通过参数stream来指定的。当函数返回时,我们无法确保复制操作是否已经启动,更无法保证它是否已经结束。我们能够得到的保证是,复制操作肯定会当下一个被放入流中的操作之前执行。传递给此函数的主机内存指针必须是通过cudaHostAlloc()分配好的内存。(流中要求固定内存)
- 流同步:通过cudaStreamSynchronize()来协调。
- 流销毁:在退出应用程序之前,需要销毁对GPU操作进行排队的流,调用cudaStreamDestroy()。
-
针对多个流:
9.1. 记得对流进行同步操作。
9.2. 将操作放入流的队列时,应采用宽度优先方式,而非深度优先的方式,换句话说,不是首先添加第0个流的所有操作,再依次添加后面的第1,2,…个流。而是交替进行添加,比如将a的复制操作添加到第0个流中,接着把a的复制操作添加到第1个流中,再继续其他的类似交替添加的行为。
9.3. 要牢牢记住操作放入流中的队列中的顺序影响到CUDA驱动程序调度这些操作和流以及执行的方式。
默认流有阻塞的作用。如图中红线所示,如果调用默认流,那么默认流会等非默认流都执行完才能执行;同样,默认流执行完,才能再次执行其他非默认流。
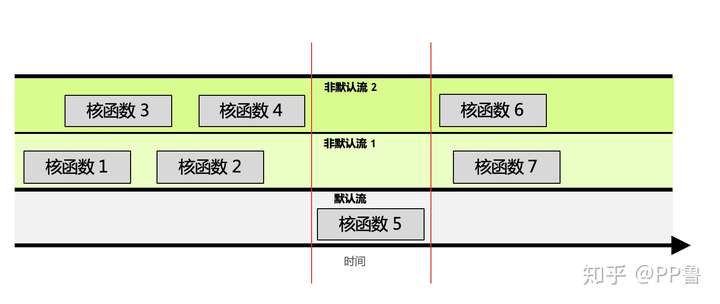
可见,某个流内的操作是顺序的,非默认流之间是异步的,默认流有阻塞作用
Memory
Global memory: 被host分配和deallocate, 然后用于初始化GPU的数据. Shared memory:只存在于block的周期里面.只能被block内部的访问
线程块(Block)
- 由多个线程组成(可以表示成一维,二维,三维,具体下面再细说)。
- 各block是并行执行的,block间无法通信,也没有执行顺序。independently, 可以并行可以按照series
- 块中的线程可以通过一些共享的内存共享数据并同步它们的执行以协调内存访问来进行协作, 可以并行也可以同步执行
- 块的好处: 可以自由安排在不同SP上面,core上面,来对应code所需要执行的计算量
- 注意线程块的数量限制为不超过65535(硬件限制)
流处理簇(SM): 有控制单元,寄存器,shared Memory
In an NVIDIA GPU, the basic unit of execution is the warp (GPU执行的最基本单元). A warp is a collection of threads, 32 in current implementations, that are executed simultaneously by an SM. Multiple warps can be executed on an SM at once.
SP:最基本的处理单元
streaming processor,也称为CUDA core。
最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。 SM:多个SP加上其他的一些资源组成一个streaming multiprocessor。也叫GPU大核,其他资源如:warp scheduler,register,shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力
thread
一个CUDA的并行程序会被以许多个threads来执行。 block:数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory (SMs) 通信。 grid:多个blocks则会再构成grid。 warp:GPU执行程序时的调度单位,目前cuda的warp的大小为32,同在一个warp的线程,以不同数据资源执行相同的指令,这就是所谓 SIMD
Threads within a block can cooperate by sharing data through some shared memory and by synchronizing their execution to coordinate memory accesses.
执行过程:
When a CUDA program on the host CPU invokes a kernel grid, the blocks of the grid are enumerated and distributed to SMs with available execution capacity. The threads of a thread block execute concurrently on one SM, and multiple thread blocks can execute concurrently on one SM. As thread blocks terminate, new blocks are launched on the vacated SMs. 当一些线程块执行完成的时候, 新的线程块就会被唤起进行执行,也就是一个dynamic的过程. 保持block是32的倍数的时候,就能保证warp被合理利用,满格利用. warp里面是并行处理, SIMT的
_ global_
One CPU thread VS One GPU thread: GPU is slower, because it has to transfer data sets between CPU and GPU
Synchronous and Asynchronous
同步操作 主机向设备提交任务,主机将阻塞,直到设备将所提交任务完成,并将控制权交回主机。然后继续执行主机的程序。
异步操作 主机向设备提交任务,设备直接开始执行任务,但主机将不再阻塞,而是直接继续执行主机的程序。主机并不会等待设备执行任务完毕。默认是异步的
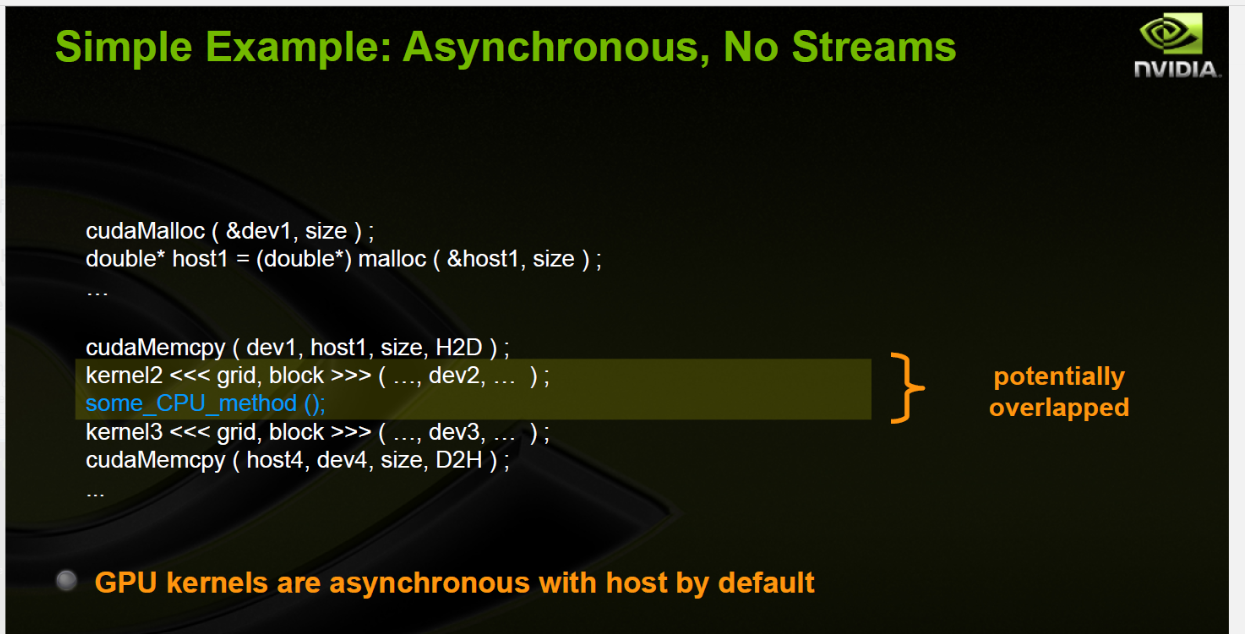
在CUDA当中,核函数kernel的执行总是异步的,而cudaMemcpy数据传输总是同步的
特别需要注意的是主机在提交核函数之后,不会阻塞等待核函数执行完毕。在profiler CUDA程序时,一定要记得添加cudaDeviceSynchronize() 同步,或者添加一个数据传输(cudaMemcpy-隐含着同步操作) ,以保证核函数执行结束。不然很容易检测不到核函数。
ECE 8823
Simple Setting
dim3 dimGrid(32,2,2);// points to blockIDx.x, blockIDx.y, blockIDx.z;
dim3 dimBlock(2,2,1); // points to threadIDx.x, threadIDx.y, threadIDx.z;
my_kernel<<<dimGrid, dimBlock,shared_memory_size, stream_number>>>(int* A, int* B, int* C);
Example: A*2
//kernel_function
__global__ void PictureKernel(float* d_Pin, float* d_Pout, int n,int m) {
// Calculate the row # of the d_Pin and d_Pout element to process
int Row = blockIdx.y*blockDim.y + threadIdx.y;
// Calculate the column # of the d_Pin and d_Pout element to process
int Col = blockIdx.x*blockDim.x + threadIdx.x;
// each thread computes one element of d_Pout if in range
if ((Row < m) && (Col < n)) {// 可能不能完全刚好匹配 16*16 之类的
d_Pout[Row*n+Col] = 2*d_Pin[Row*n+Col];
}
}
Example: Simple Matrix Multiplication
Simple Method
//kernel_function
__global__ void SimpleMultiplication(float* d_M, float* d_N, float* d_out int n,int m) {
// Calculate the row # of the d_Pin and d_Pout element to process
int Row = blockIdx.y*blockDim.y + threadIdx.y;
// Calculate the column # of the d_Pin and d_Pout element to process
int Col = blockIdx.x*blockDim.x + threadIdx.x;
// each thread computes one element of d_Pout if in range
if ((Row < m) && (Col < n)) {// 可能不能完全刚好匹配 16*16 之类的
for (int k = 0; k < Width; ++k)
{
d_out += d_M[Row*Width + k]*d_N[k*Width + column];
}
}
}
Tile Method
// Setup the execution configuration
// TILE_WIDTH is a #define constant
dim3 dimGrid(Width/TILE_WIDTH, Width/TILE_WIDTH, 1);
dim3 dimBlock(TILE_WIDTH, TILE_WIDTH, 1);
// Launch the device computation threads!
MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width);
__global__ void MatrixMulKernel(float* d_M, float* d_N, float* d_P, int Width)
{
// Calculate the row index of the d_P element and d_M
int Row = blockIdx.y*blockDim.y+threadIdx.y;
// Calculate the column idenx of d_P and d_N
int Col = blockIdx.x*blockDim.x+threadIdx.x;
if ((Row < Width) && (Col < Width)) {
float Pvalue = 0;
// each thread computes one element of the block sub-matrix
for (int k = 0; k < Width; ++k)
Pvalue += d_M[Row*Width+k]*d_N[k*Width+Col];
d_P[Row*Width+Col] = Pvalue;
}
}
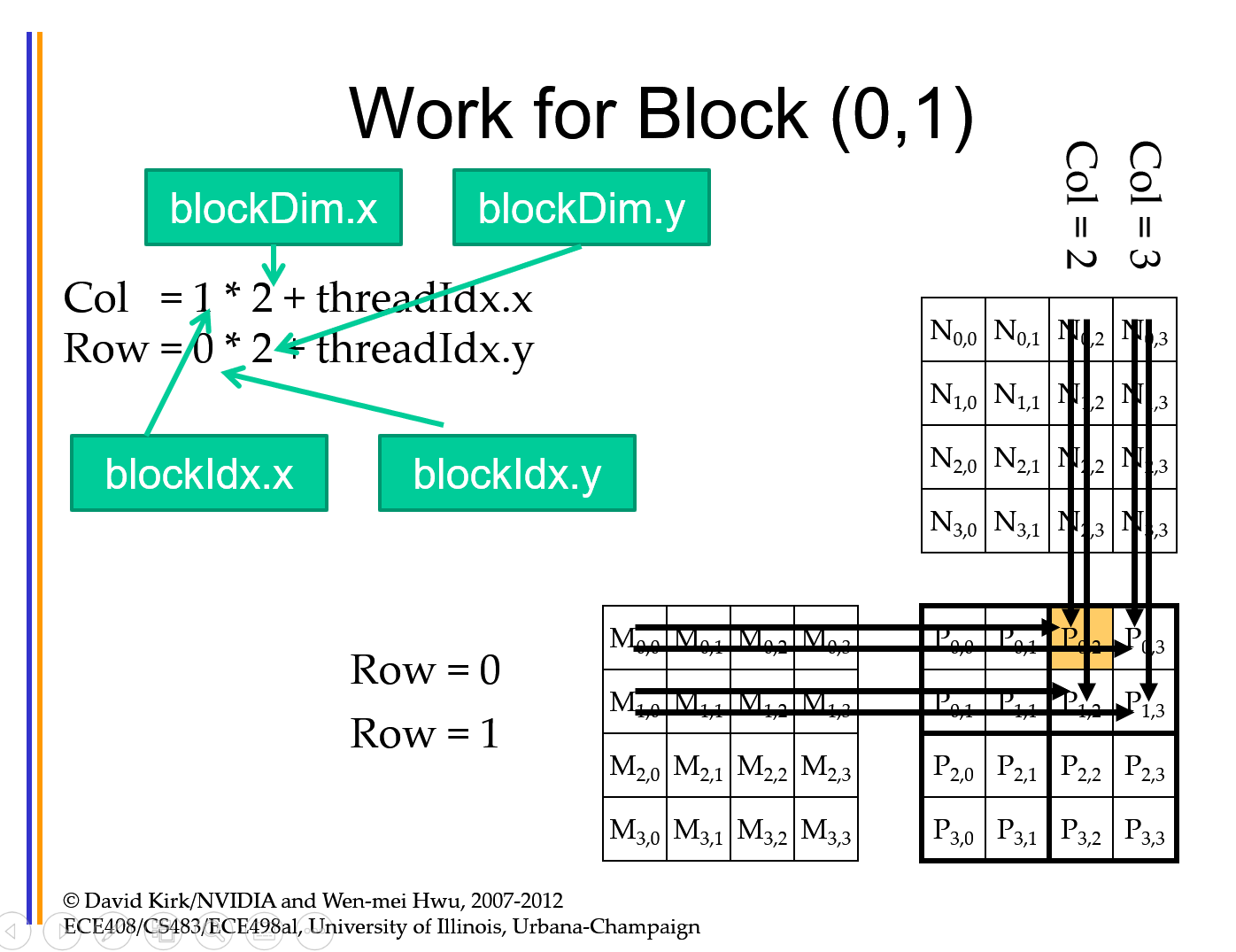
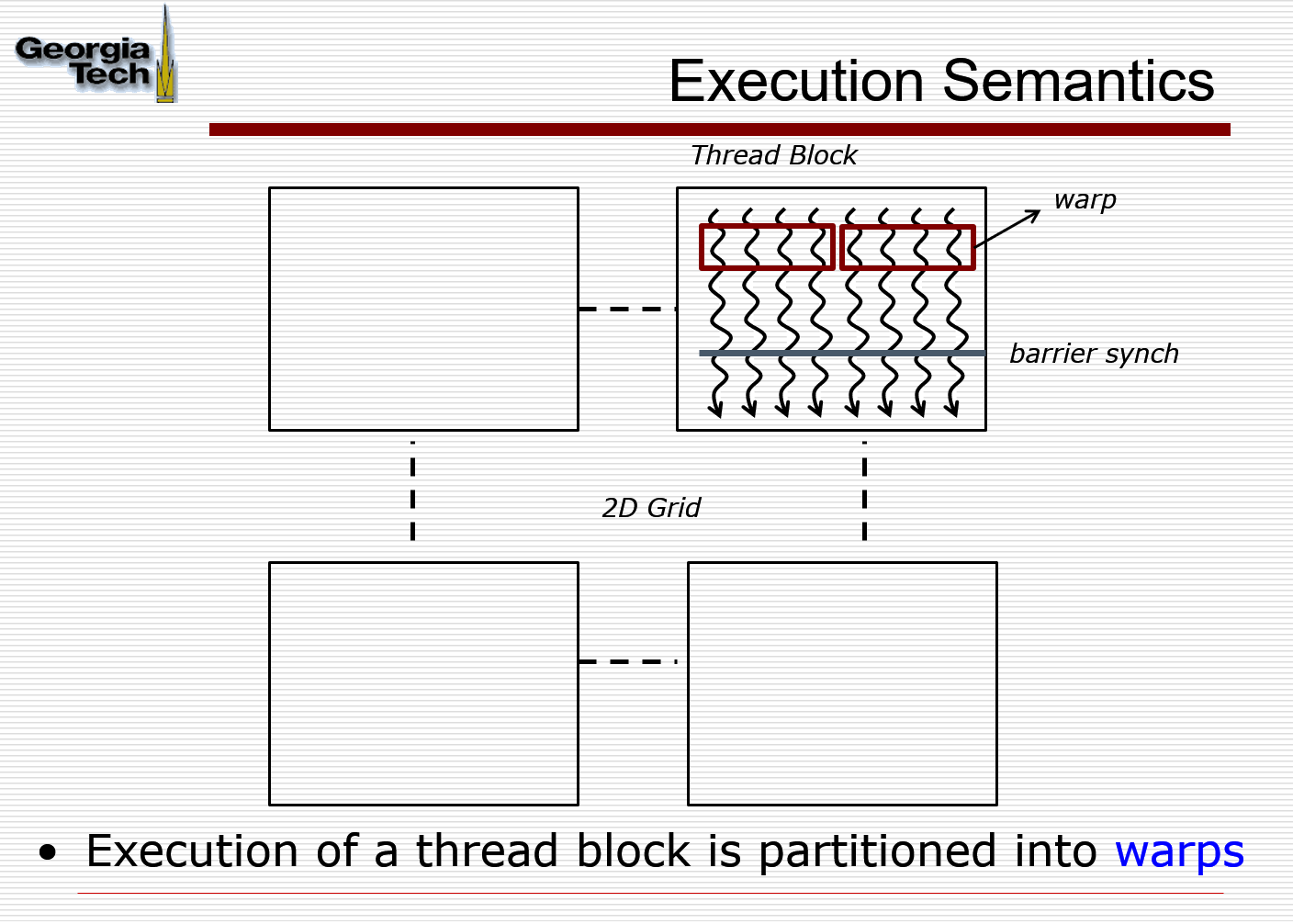
Kernel Execution Model
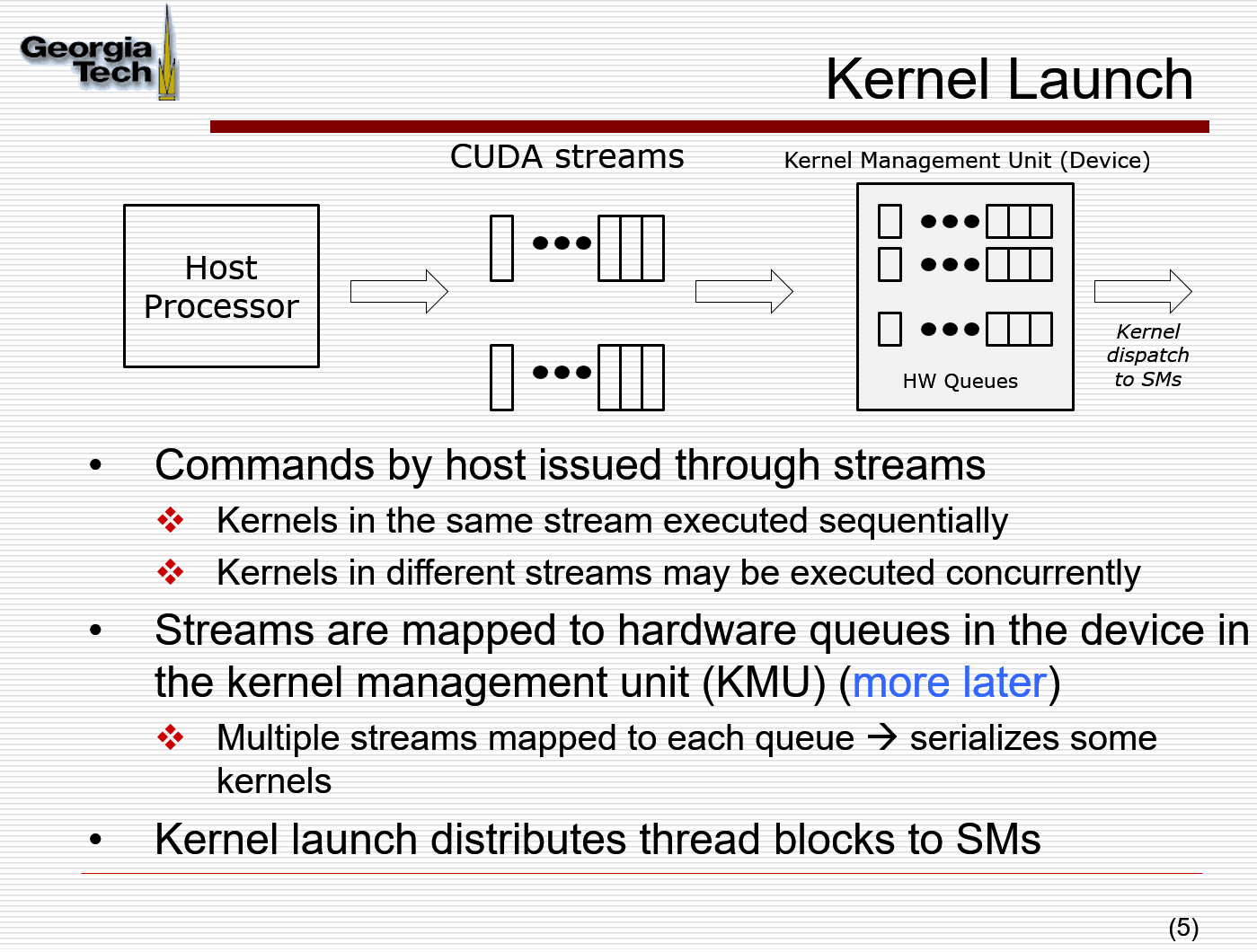
Kernel Launch Distributes thread blocks to SMs
All threads in a block execute the same kernel program (SPMD), also referred to as cooperative thread arrays (CTAs)
Threads in the same block share data and synchronize while doing their share of the work. 同一个block里面的thread执行一样的kernel function 以及 在 做他们share 的工作 的时候同步 !!
Barrier Synchronization !!! (同步的!!!);不同blocks之间是独立的,不共享内存,所以是异步的! blocks可能按照任意顺序执行,提高可伸缩性 hardware is free to assign blocks to any processor at any time.
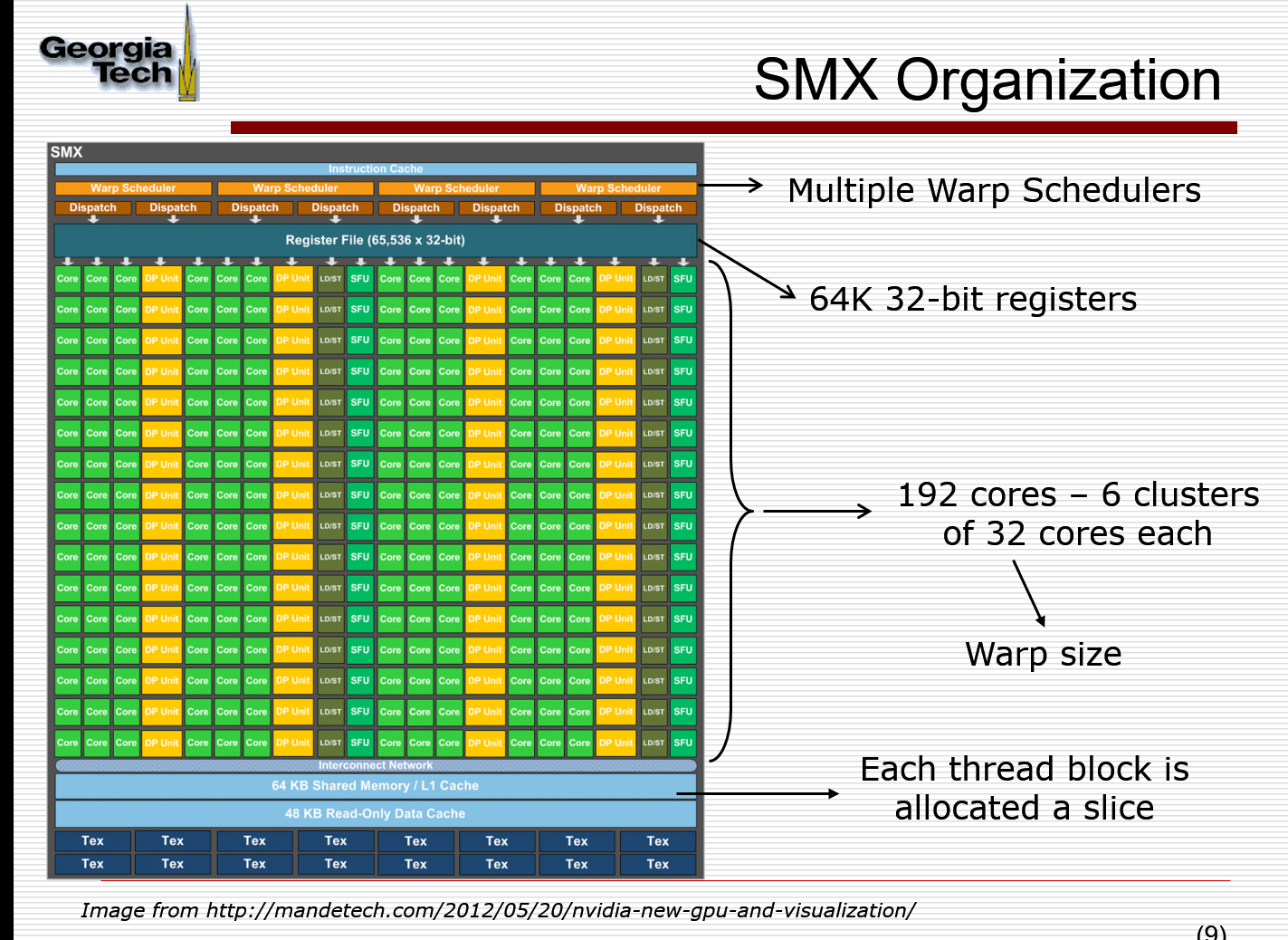
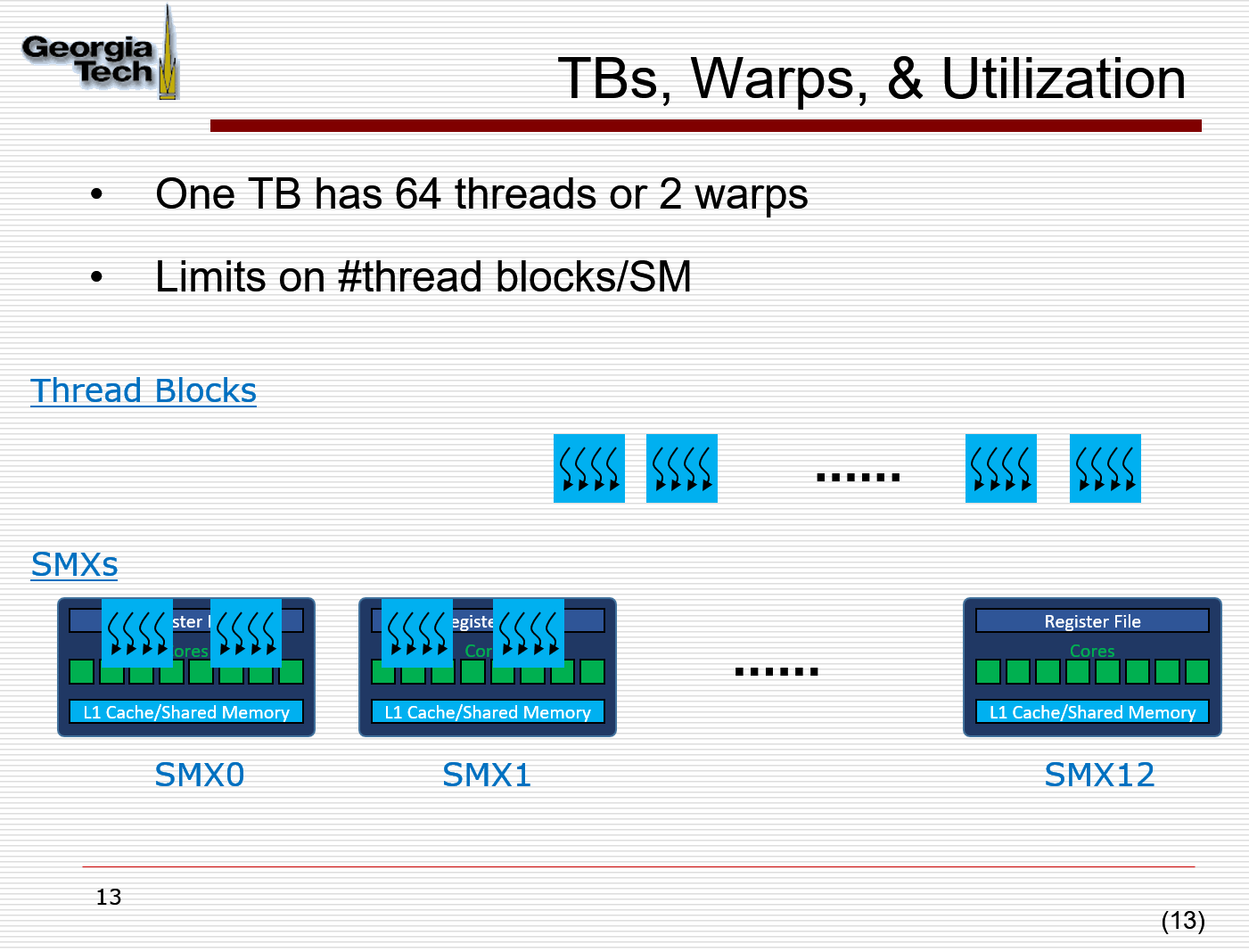
每一个block对应多少个warp,分配到SM cores的时候,就是按照warp进行分配的,比如一个SM只能运行两个warp,当所有SM core都能填满的时候,其他就会等待, Remaining ThreadBlock are queued.
Thread Blocks partitioned
thread IDs within a warp are consecutive and increasing !!! 不要依靠warp的order, 如果有dependency的话还是需要用__synnthreads() to get correct results.
All threads in a warp execute the same instruction when selected !!
why blocks is limited on SM? Resource Limits on Occupancy
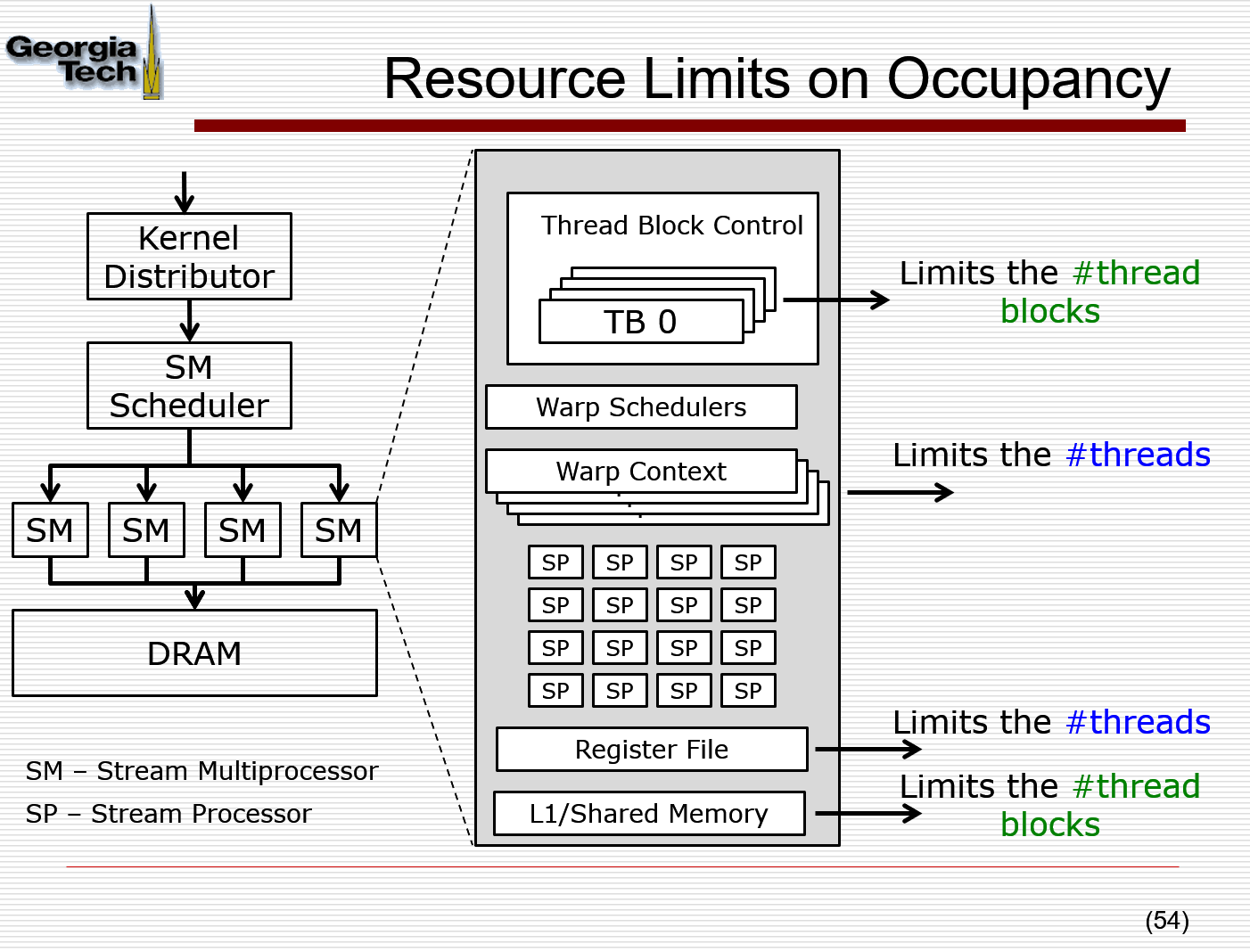 warp context, register file, L1/Shared Memory
warp context, register file, L1/Shared Memory
Why 16*16 block size
occupancy is the ratio of active warps to maximum supported active warps;
BLock: 16*16这样好被warp分配,占用满格warp,提高利用率 The SM has a maximum number of blocks that can be active at once; 但是每个SM只能占据固定数量的Block,这样thread占有率就成了最大问题,如果block size 太小,那么占有率不高,这样也就不能弥补一些latency。 如果BLock里面线程过多,占用资源也就越多,可能会导致活跃的block的数量不够多。
 所以一般用16*16!!!
所以一般用16*16!!!
Shared Memory is allocated per thread block. 如果block size过大,那么increase register pressure, shared memory pressure; lower pressure on thread block slots and thread slots.
Goal: Increase occupancy until one or the other is saturated
The number of threads per block should be a round multiple of the warp size, which is 32 on all current hardware. Each streaming multiprocessor unit on the GPU must have enough active warps to sufficiently hide all of the different memory and instruction pipeline latency of the architecture and achieve maximum throughput. The orthodox approach here is to try achieving optimal hardware occupancy.
Streams and Events
Streams: usage to overlap GPU computation and data transfers; usage to improve GPU utilization: multi-kernel execution on the GPU (for later devices)
Events: usage in timing of GPU kernel execution
Streams

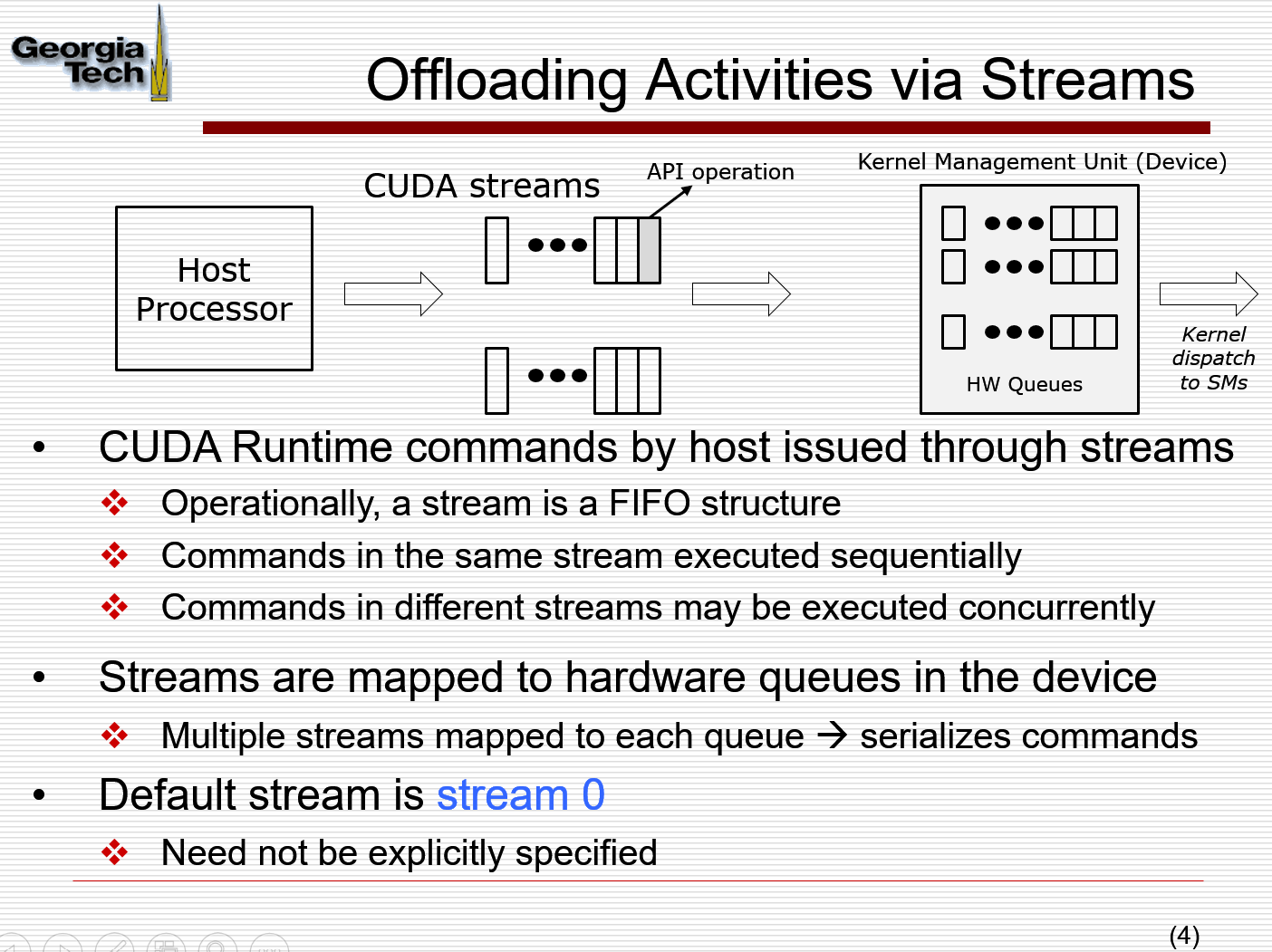
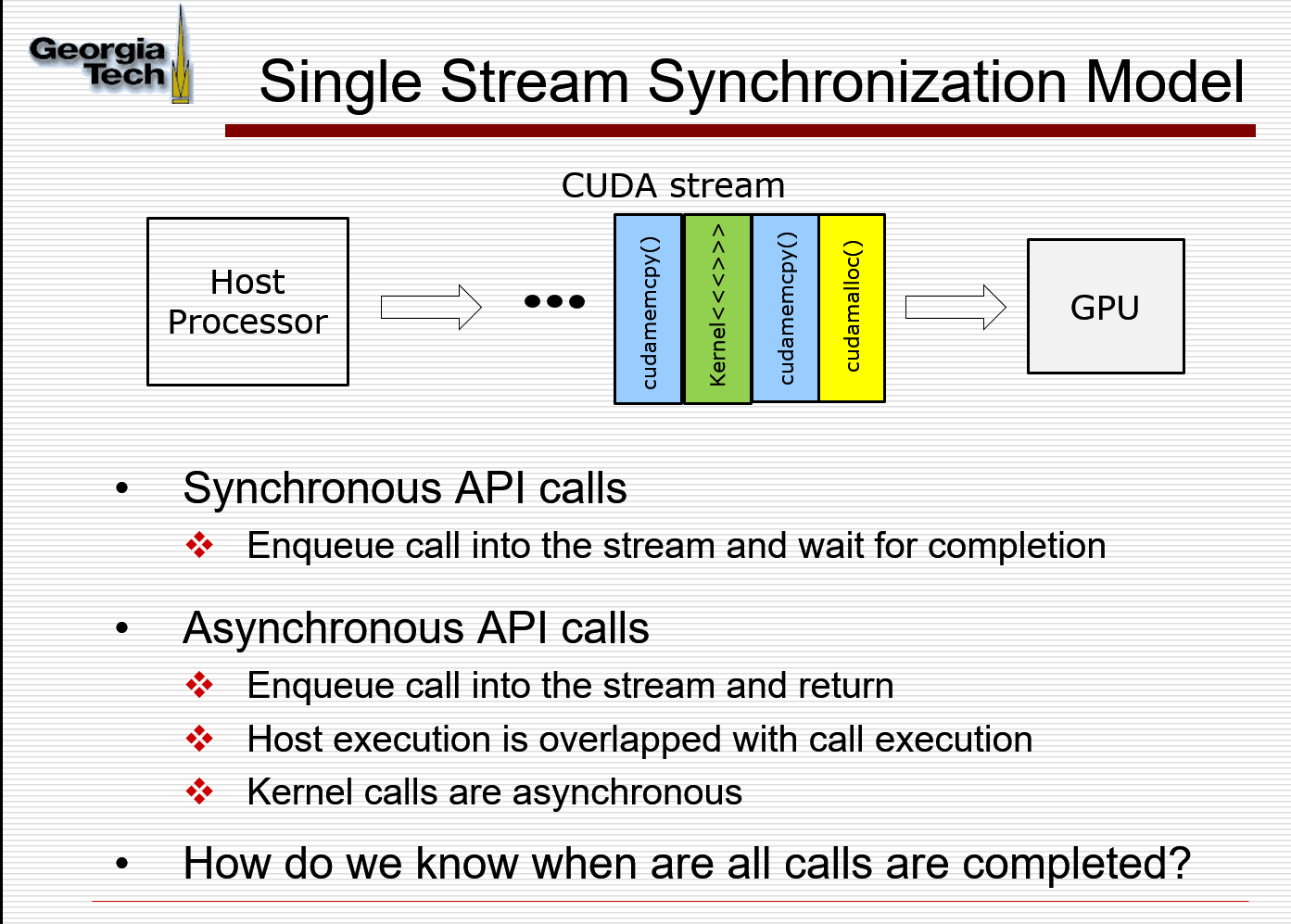
cudamemcpy is synchronous; kernel calls are asynchronous with CPU Host
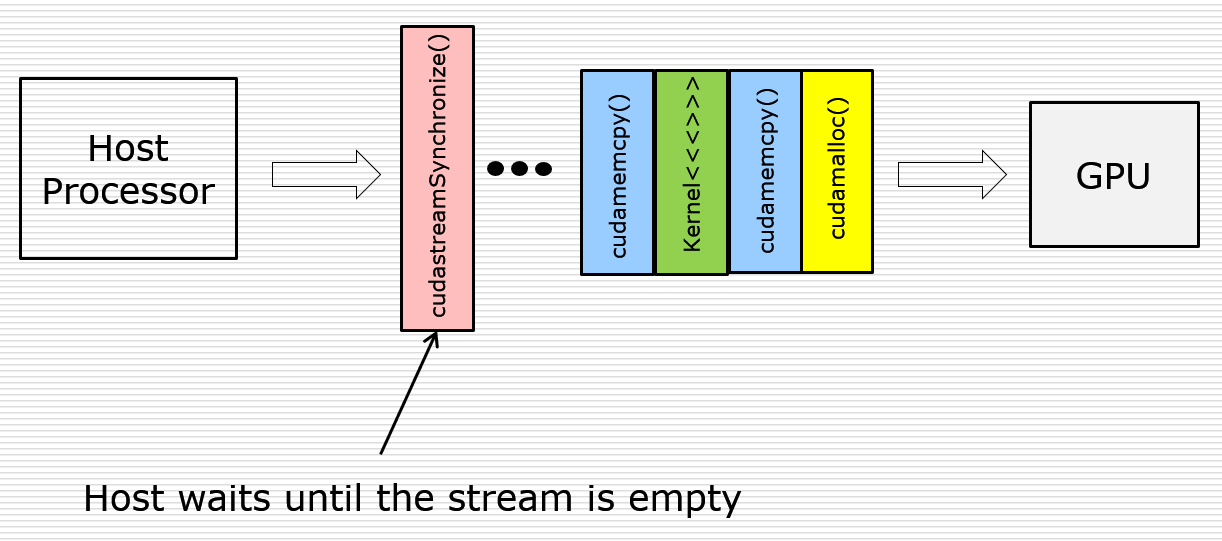
cudaStream_t stream
cudaStreamCreate(&stream);
cudaStreamDestroy(stream);
kernel<<< blocks , threads, stream>>>();
Events
create event to record timestamps; place event into the stream; Time will be recorded on the GPU when the event is processed at the GPU;
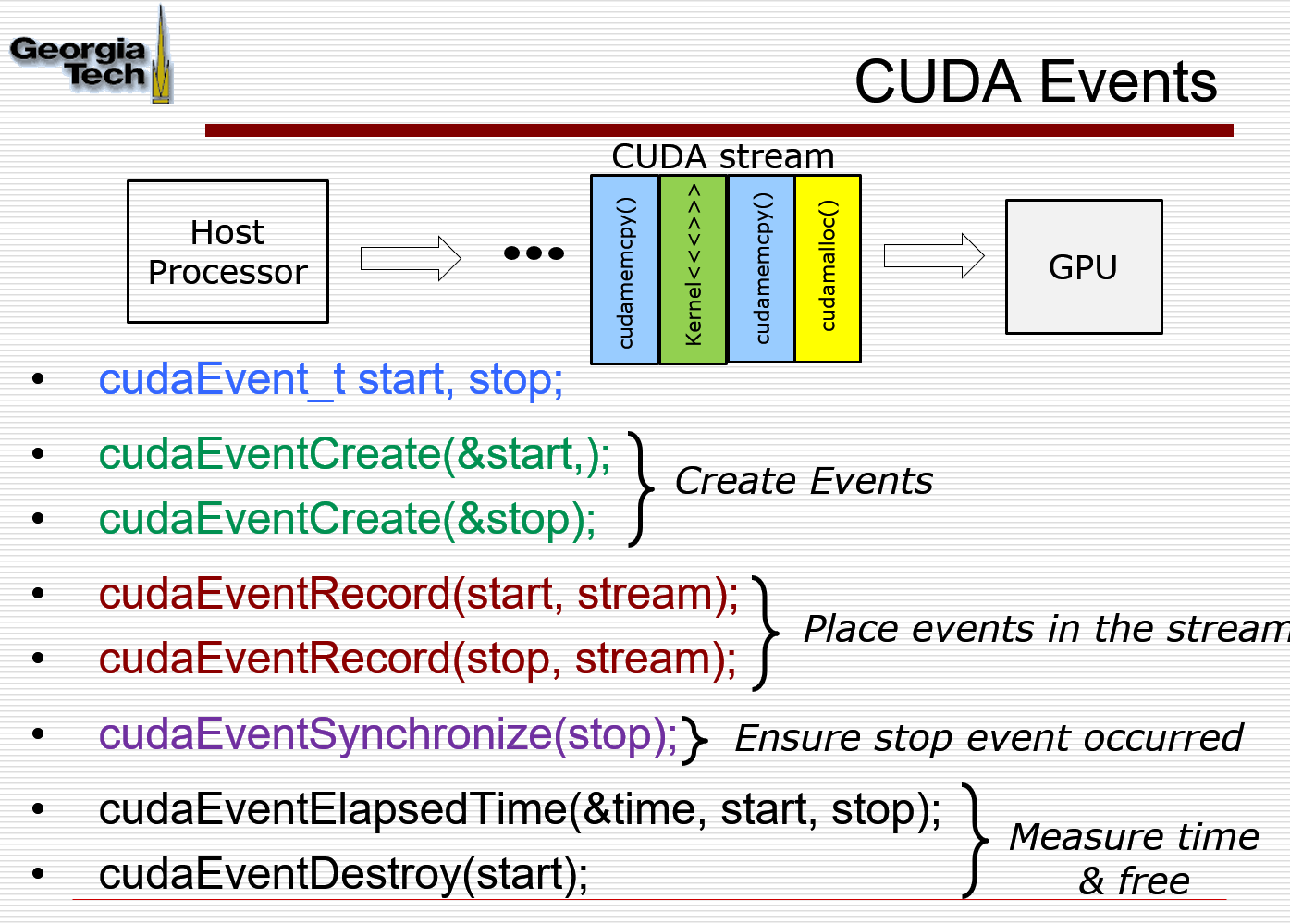
Need to ensure that this event is executed before reading the counters. Use cudaEventSynchronize() on host
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaMemcpy(d_x, x, N*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, N*sizeof(float), cudaMemcpyHostToDevice);
cudaEventRecord(start);
saxpy<<<(N+255)/256, 256>>>(N, 2.0f, d_x, d_y);
cudaEventRecord(stop);
cudaMemcpy(y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost);
cudaEventSynchronize(stop);
float milliseconds = 0;
cudaEventElapsedTime(&milliseconds, start, stop);
cudaEventDestroy (start); cudaEventDestroy(stop);
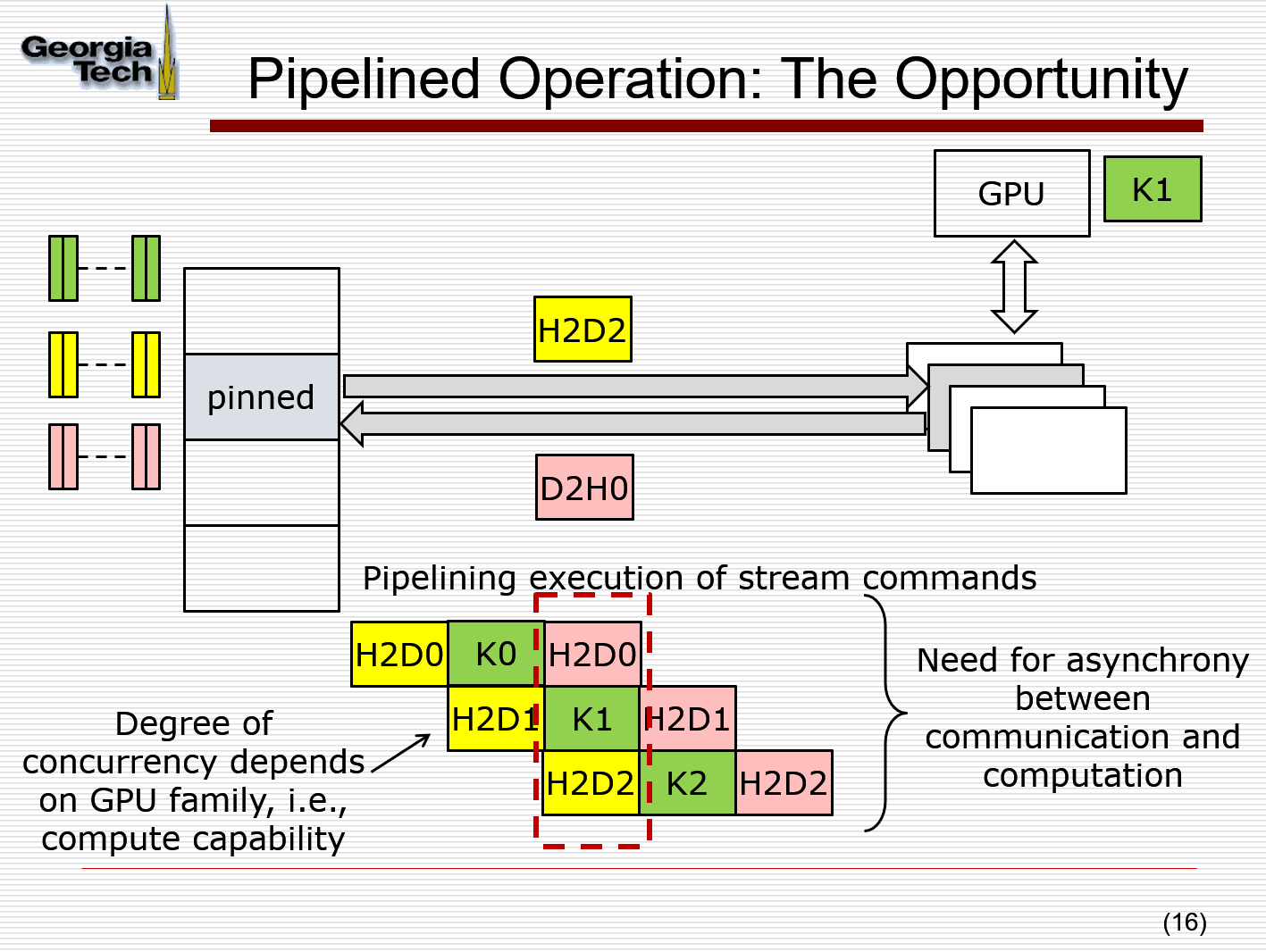
Asynchronous Communication
Apply DMA (direct memory access) 通过直接物理内存,速度更快,不分页;也能保证数据不会被移除到Disk上面。
需要cudaMemecpyAsync()

Memory Model
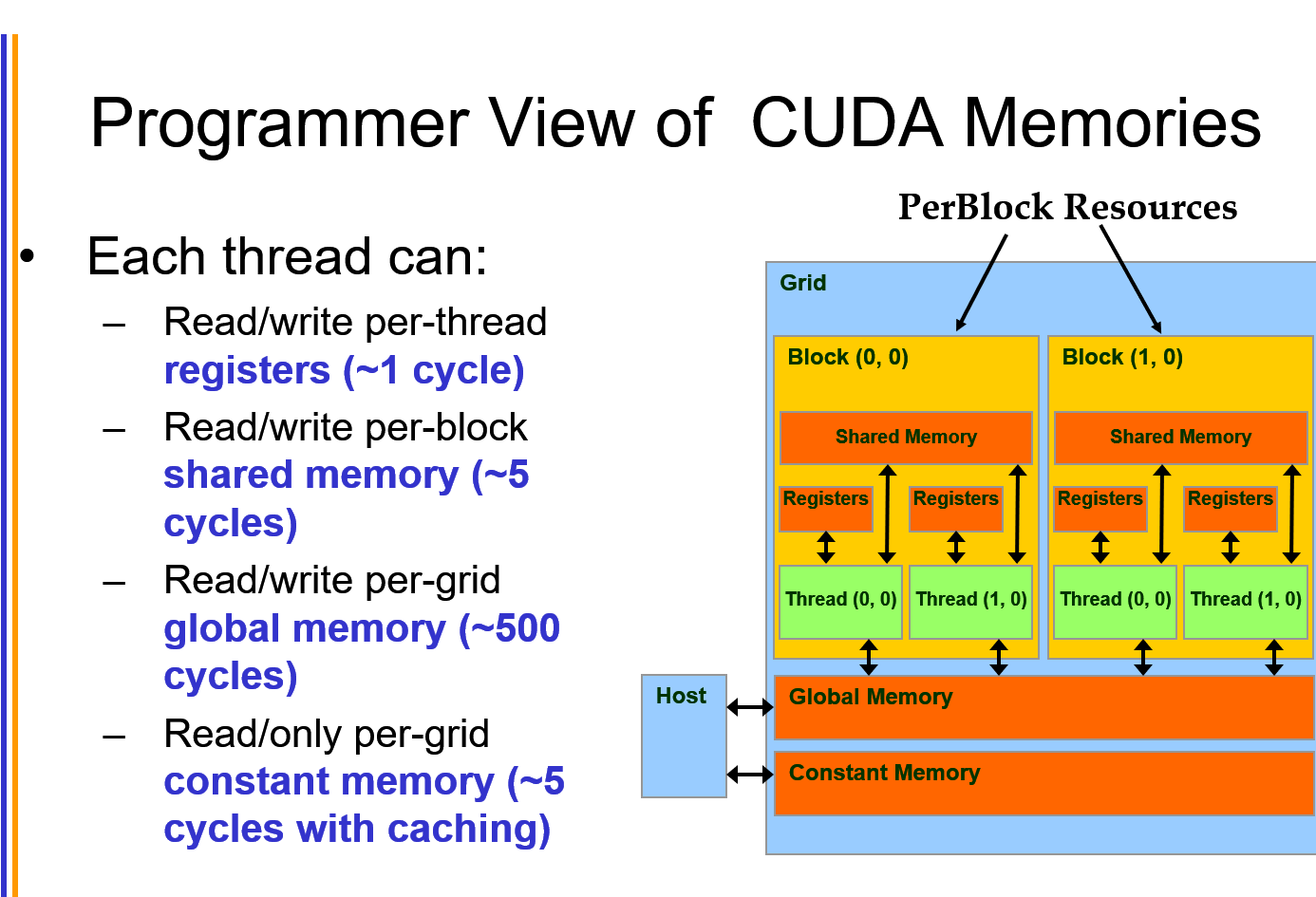
Automatic Variables: global memory, registers 自动分配的
int LocalVar 是存在于 register中的,随thread消亡。如果是array,需要index,那就会存在local memory里面,local memory本质是和global memory是一样的;
Constant Memory: Constant Cache
Constant variable不是在kernel function 里面定义的,而是在 host 上面, 通过
cudaMemcpyToSymbol(M,tempM,size);
Shared Memory

Remember to synchronize after shared memory loading

把输入两个矩阵和输出矩阵都按照tile划分计算



1D: row*N + col; hei*N*N + row*N + col
2D: [row][col]
3D: [row][col][heig]
__global__ void MatrixMulKernel(float* d_M, float* d_N, float* d_P, int Width)
{
__shared__ float ds_M[TILE_WIDTH][TILE_WIDTH];
__shared__ float ds_N[TILE_WIDTH][TILE_WIDTH];
int bx = blockIdx.x; int by = blockIdx.y;
int tx = threadIdx.x; int ty = threadIdx.y;
// Identify the row and column of the Pd element to work on
int Row = by * TILE_WIDTH + ty;
int Col = bx * TILE_WIDTH + tx;
float Pvalue = 0;
// Loop over the Md and Nd tiles required to compute the Pd element
for (int m = 0; m < Width/TILE_WIDTH; ++m) {
// Collaborative loading of Md and Nd tiles into shared memory
ds_M[ty][tx] = d_M[Row*Width + m*TILE_WIDTH+tx];
ds_N[ty][tx] = d_N[Col+(m*TILE_WIDTH+ty)*Width];
__syncthreads();
for (int k = 0; k < TILE_WIDTH; ++k)
{
Pvalue += ds_M[ty][k] * ds_N[k][tx];
}
__syncthreads();
}
d_P[Row*Width+Col] = Pvalue;
}
Each SM in Fermi has 16KB or 48KB shared memory*

Question?
- Parallel
- race condition: threads run asynchronously. Fork and then Join.
- critical section: a section of code where it is guaranteed that at most one thread can be executing in a critical section at one time. code that accesses and modifies shared variables, must be placed within a critical section
- solution: perform and read-then-write as a single, atomic operation. Read data and set locked at the same time.
- Dead Locks: the program stops when one occurs (easy to detect deadlocks)
- –> 1. impose a fixed sequence in which locks must be obtained
-
—> 2. if holding a lock , don’t try to acquire another lock.
- 为什么有block以及thread?
- 一个thread的寄存器存储什么信息?6010 Slides, IR, PC等等 Program Counter: 指向下一个计算机指令 General Purpose Registers: operands and results
-
CPU 单元: CPU的结构主要包括运算器(ALU, Arithmetic and Logic Unit)、控制单元(CU, Control Unit)、寄存器(Register)、高速缓存器(Cache)和它们之间通讯的数据、控制及状态的总线。
-
为什么cache 越来越大? 很简单,延迟开销/命中时间的影响。l1致力于更快的速度,l2才是致力于命中率。的确,把Cache做大后缺失率自然就低了——然而最终的标准是整个存储器对程序执行时间影响,这其中还有延迟开销和命中时间以及影响。
- 为什么 void ** 因为首先声明了 float * a, 再去做cudaMalloc, a的值不会变,也就是pointer的值不会变,而实际上新赋值的p会改变值,这样还是不能通过a去访问,必须知道pointer地址,再将pointer的值赋值给pointer所在的地址
寄存器
速度最快的内存空间,GPU 寄存器储量多一些 储存不加修饰的声明变量,以及常数长度的数组
if this factor is limiting active blocks, it means the number of registers per thread allocated by the compiler can be reduced to increase occupancy
可以减少分配给每个线程的register的数量,这样Occupancy就增加了
寄存器堆每个线程是私有的,声明周期和核函数一样,执行完就不能访问了。
寄存器是SM的稀有寄存器,一个线程如果使用更少的寄存器,那么就会有更多的常驻线程块。SM上并发的线程块越多,效率越高,性能和使用率也就越高。
线程中变量太多,就会溢出到local Memory,速度就会很慢。和全局内存在同一块区域里面。 local Memory 会存储 未知索引的数组,占用寄存器空间较大的。
共享内存
避免内存竞争的时候,__syncthread(); 每个SM都有一定数量的共享内存,过度使用共享内存,会导致SM上活跃的线程束减少。生命周期和线程块一致。
定义在线程块里面,写死的。
__shared__ float ANS[256];
共享内存是按照 Bank划分的,这里GPU是一次性访问banks数量的地址,获得这些地址上的所有数据,并且映射到不同的bank上。读写n个地址,变成了读写b个独立的banks中每个读写n个数据,所以有效带宽就提高到了b倍。
如果每个线程访问不同的bank,那么就能一次性访问多个data。 按照规定,每个bank每次只能访问一个dataset.如果半个 warp 访问16个不同的warp,就能实现最快的速度。
缓存
CPU 读写都有可能缓存,但是GPU 写的过程中不缓存,只有加载的时候缓存。
全局内存
是通过 L2 缓存和每个SM连接的 全局内存访问是对齐的,burst 访问,也就是一次要读取指定大小整数倍字节的内存。
cudaError_t; // 一个标记符,表示是否成功
内存访问
Unified 内存 可以 同时被CPU和GPU访问。
cudaMallocManaged();
Warp
instructions are SIMD-synchronous within a warp No need to use __syncthreads();
GPU线程切换很快的原因
主要是每个线程都有自己的寄存器,不需要上下文切换,所有需要的data都储存在shared_memory里面
CPU,GPU支持线程的方式不同,CPU每个核只有少量寄存器,在执行多任务的时候, 上下文比较昂贵,因为需要将寄存器里的数据保存到RAM,重新执行任务时,需要从RAM中恢复。 而GPU上下文切换只需要设计一个寄存器组调度着,用于将当前寄存器里的内容换进换出, 速度比保存到RAM快好几个数量级。
CPU在线程数增加的时候,上下文切换时间会很多,通常这个时候在进行I/O操作或者内存获取, 这个时候CPU会被闲置。而GPU采用的是数据并行模式,他需要成千上万的线程操作。利用有效 的工作池保证GPU不会被闲置。GPU默认是并行模式,SM每次可以计算32个数,而CPU只计算1个。 GPU的每个SM都有一个内部访问的共享内存和寄存器,SP与寄存器交流速度很快,几乎不用等。 处理的数据可以在放在共享内存,不用担心上下文切换需要转移。
global and device
Device functions can only be called from other device or global functions. device functions cannot be called from host code
CUDA优化 !!!
优化策略

Minimize use of low-throughput instructions
Use high precision only when necessary
minimize divergent warps




通信:数据传输 – 锁页内存


分支:if else
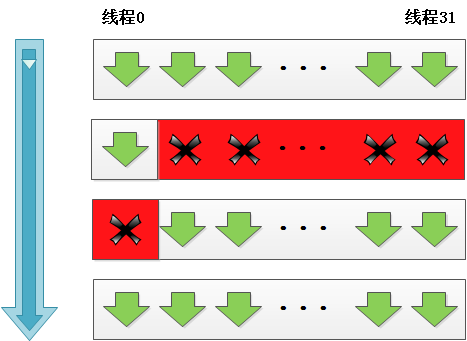
cuda 执行 if else 语句的效率非常低。 由于判断产生了分支,所以导致第二行和第三行是串行执行的。 我们在编程的时候尽量让warp对齐instruction。
warp对齐还能使得访问shared memory bank,同时访问一连串数字,效率很高。
AllReduce
Why multiple Blocks?
因为SM上面有多个block,如果只使用一个的话,这样就会造成资源的浪费,不够高效。
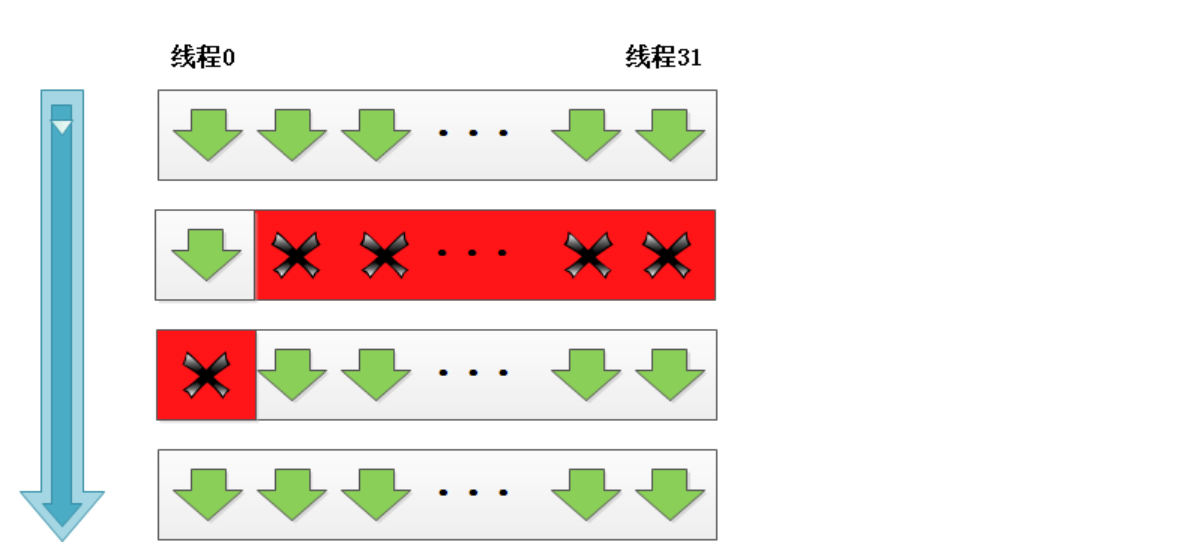
Synchronization of Multiple BLocks
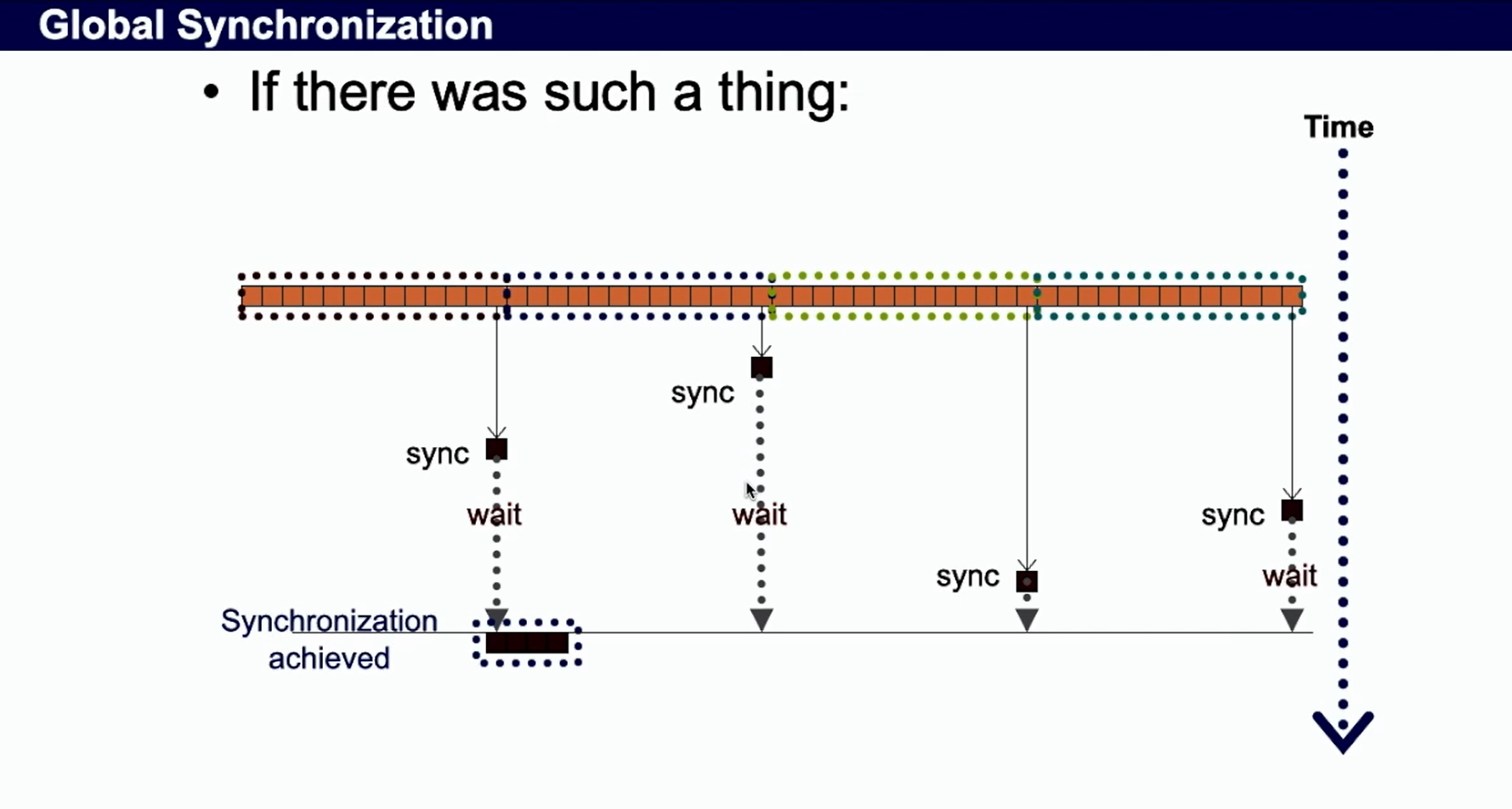
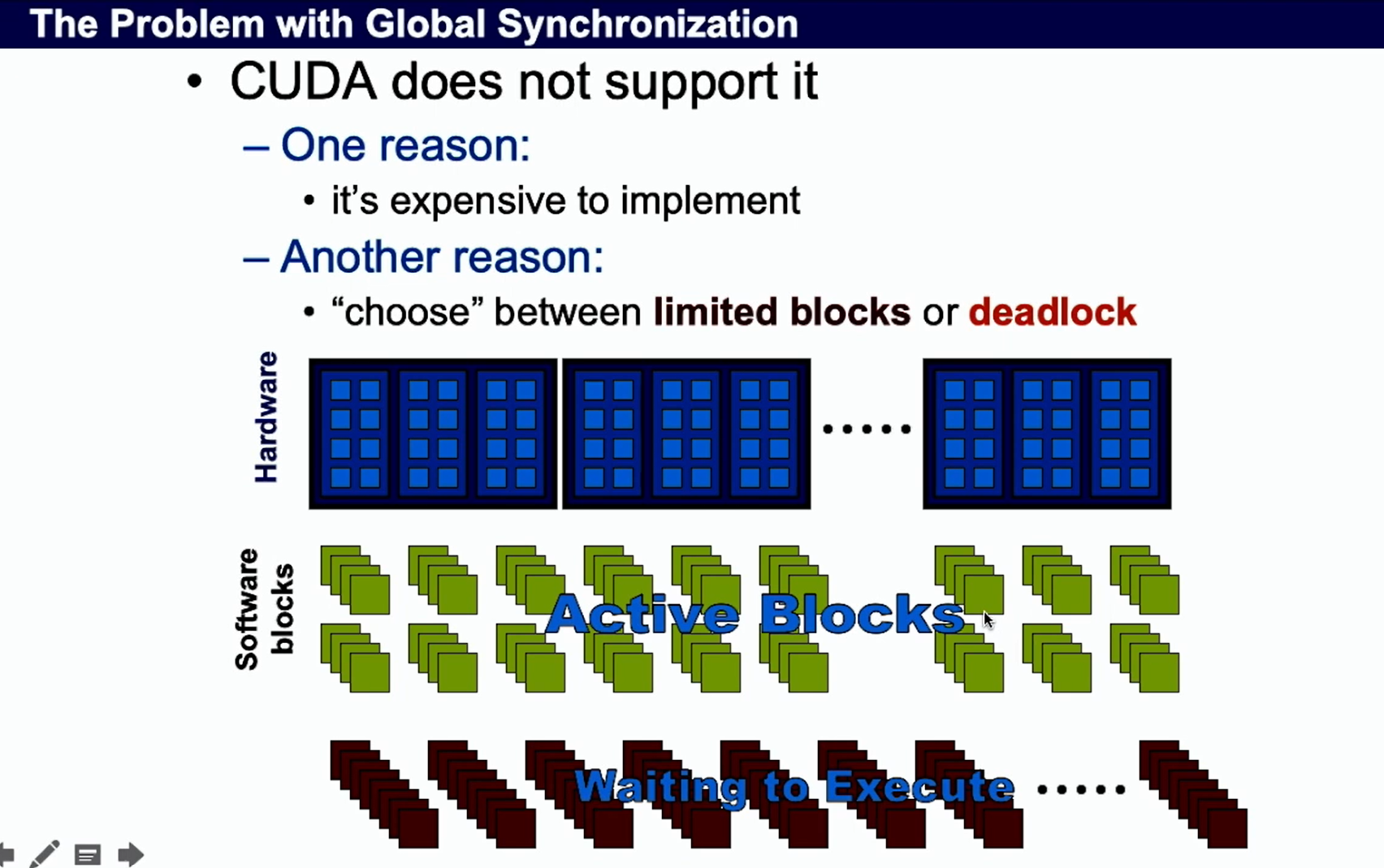
Why don’t have global sync
- block等待,浪费资源
- 造成死锁,块太多,SM就要一直等待,再安排其他warp
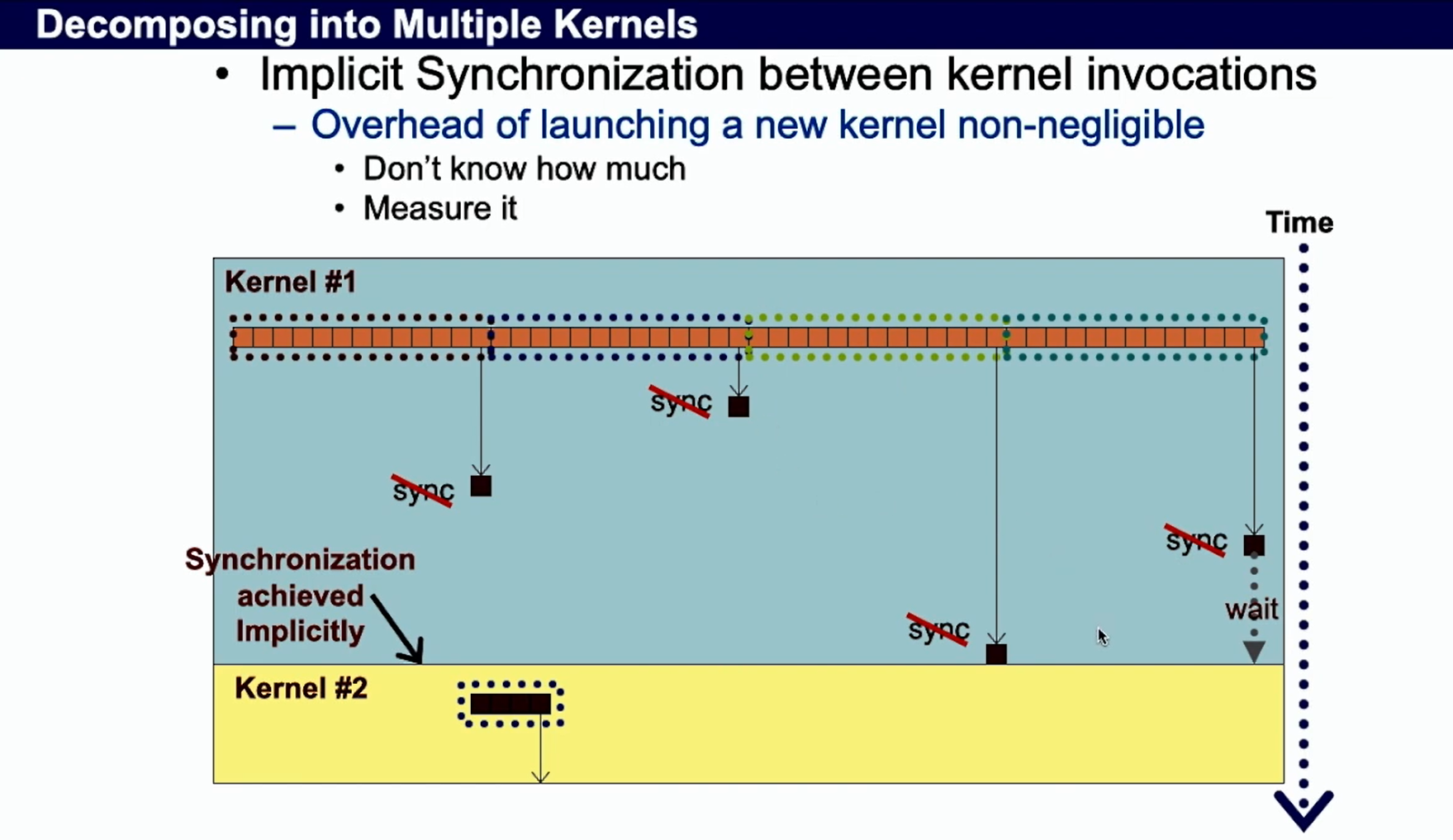
how to sync several blocks ? 不同 kernel
二叉树算法

每个线程读取一个item from global to shared
Version 1
__shared__ float partialsum[256];
unsigned int tid = threadIDx.x;
unsigned int i = threadIDx.x + blockIDx.x*blockDim.x;
partialsum[tid] = g_idata[i];
__syncthread();
For (unsigned int stride =1; stride <blockDim.x; stride *=2)
{
If(t%(2*stride) == 0)//不同的线程执行的命令不一样
partialsum[tid] +=partialsum[tid+stride];
__syncthread();
}
if (t == 0) g_odata[blockIDx.x] = sdata[0];
同一个warp里不同的线程执行的命令不一样,偶数的话就计算,不是的话就等待,这就是浪费。
Version 2: optimized – 一半一半
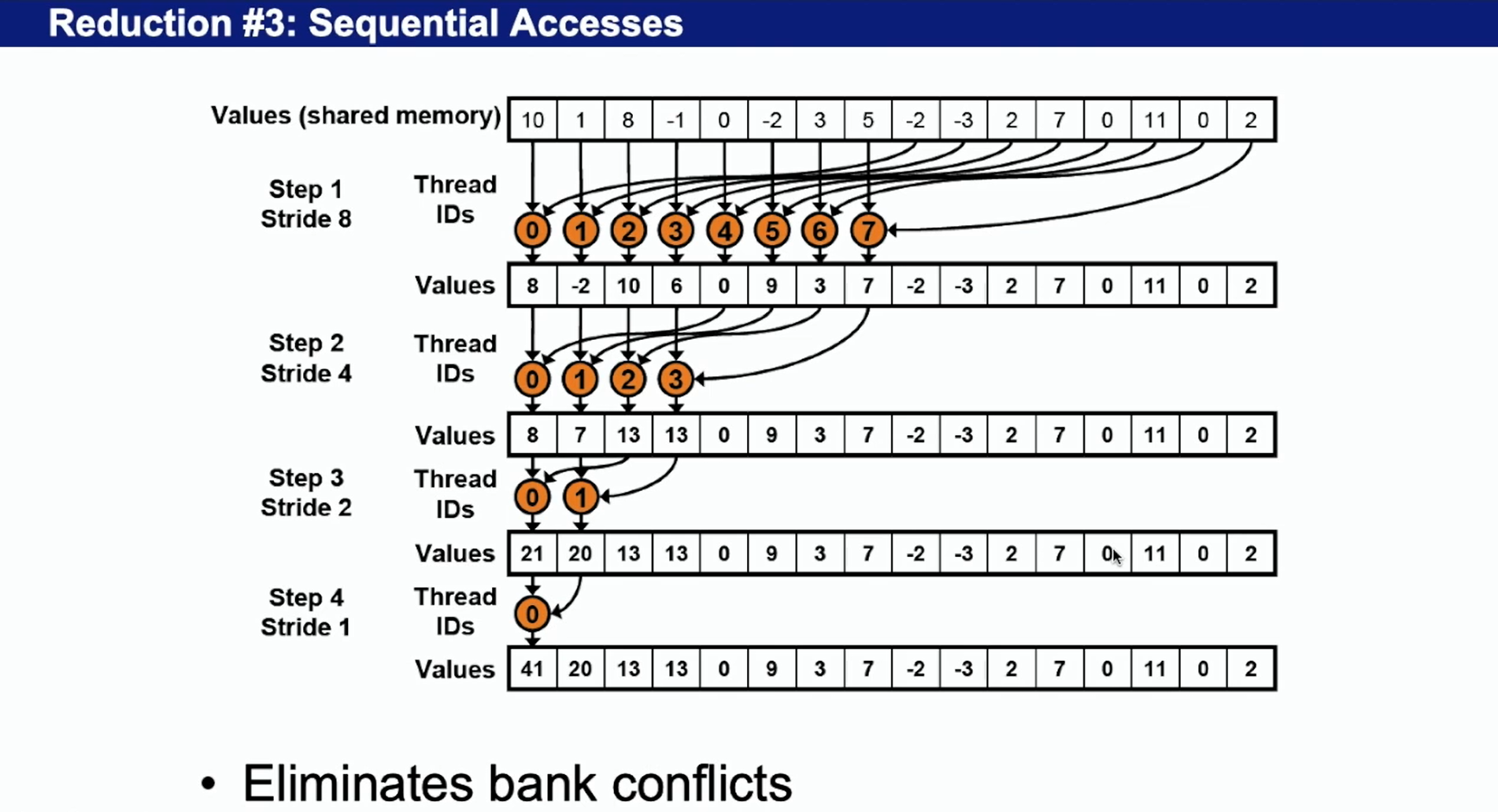
可以避免 bank conflict, 如果同时访问一个bank就会效率低下。
让一个warp里面的尽可能做一样的指令,不要diverge
__shared__ float partialsum[256];
unsigned int tid = threadIDx.x;
unsigned int i = threadIDx.x + blockIDx.x*blockDim.x;
partialsum[tid] = g_idata[i];
__syncthread();
For (unsigned int stride = blockDim.x/2; stride > 0; stride /=2)
{
if (tid < stride)
{
partialSum[tid] += partialSum[tid + stride];
}
__syncthread();
}
if (t == 0) g_odata[blockIDx.x] = sdata[0];
Version 3: optimized – 共享内存的优化
orginal!!
unsigned int tid = threadIDx.x;
unsigned int i = threadIDx.x + blockDim.x*blockIDx.x;
sdata[tid] = g_idata[i];
__syncthread();
optimized!! Read two and do the first reduction step;
unsigned int tid = threadIDx.x;
unsigned int i = blockIDx.x*blockDim.x*2 + threadIDx.x;
sdata[tid] = g_idata[i] + g_idata[i+blockDim.x];
__syncthreads();
Version 4: optimized – Warp 的优化
当小于32的时候,一个warp里面是SIMD同步的,不需要__syncthreads();每个指令是隐性同步的,在一个warp里面。

for (unsigned int stride = blockDim.x/2; stride > 32; stride /=2)
{
if (tid < stride)
{
partialSum[tid] += partialSum[tid + stride];
}
__syncthread();
}
if (tid < 32)
{
sdata[tid] += sdata[tid+32];// 因为在一个warp里面所以所有instruction是同步的
sdata[tid] += sdata[tid+16];
sdata[tid] += sdata[tid+8];
sdata[tid] += sdata[tid+4];
sdata[tid] += sdata[tid+2];
sdata[tid] += sdata[tid+1];
}
Version 5: optimized – 完全展开

内积例子
先把乘积放入到shared memory;
syncthreads()
同步的是block 或者是 warp __syncthreads() waits until all threads within the same block has reached the command and all threads within a warp - that means all warps that belongs to a threadblock must reach the statement.
Warp
each warp executed SIMD single instruction multiple Dataflow bundle
Divergence of Warp: inefficient
Branches lead serialization branch dependent code

Causes: traditional nested branches; loops related to thread ID; switching on thread ID;
No divergence: we make threads work in one warp if possible instead of two warps
Reduction: inefficient

Inefficient: they are separate in different warps, we should converge them
__shared__ float partialsum[];
unsigned int t = threadIDx.x;
For (unsigned int stride =1; stride <blockDim.x; stride *=2)
{
__syncthread();
If(t%(2*stride) == 0)
partialsum[t] +=partialsum[t+stride];
}
// My version: inefficient
__shared__ partialSum[];
unsigned int t = threadIDx.x;
for (unsigned int i = 1; i < blockDim.x; i *= 2)
{
if (t%i == 0)
{
partialSum[t] += partialSum[t+i];
}
__syncthread();
}
Reduction: efficient
Keep the active threads consecutive
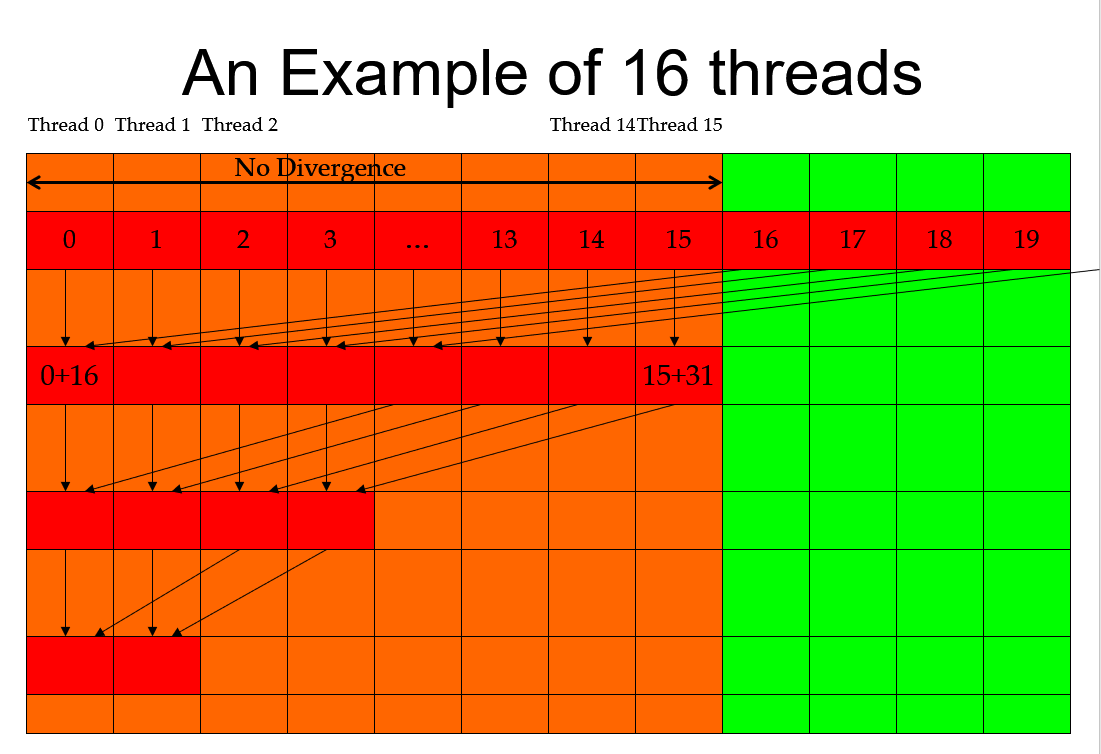
__shared__ float partialSum[];
unsigned int t = threadIDx.x;
// here blockDim.x = 32 ,one warp;
for (unsigned int i = blockDim.x; i >= 0; i /=2)
{
if (t <= i)
{
partialSum[t] += partialSum[t+i];
}
__syncthread();
}
DRAM Memory Access

Coalesce these accesses to create smaller number of memory transactions maximize memory bandwidth 整合所有memory的访问,从而一次性访问很大的数据量,使得带宽满载;最好访问连续的内存区域。
Reduce the request rate to L1 and DRAM; 减少访问的频率,最好一次性访问足够大的内存。
DRAM: burst 机制,如果都放在连续的一行,能够快速访问。类似于收费站
Modern DRAM systems are designed to be always accessed in burst mode. Burst bytes are transferred butdiscarded when accesses are not to sequential locations.
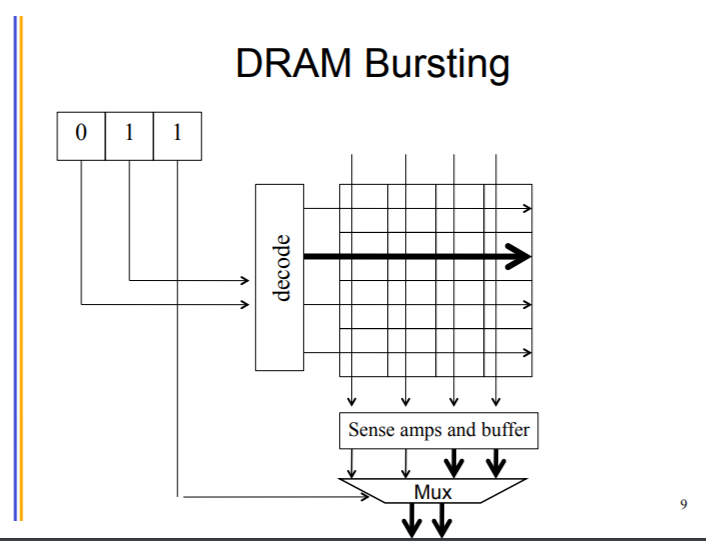
下面的例子中就相当于只写入一次大数据,这样会很快。因为 Pvalue是放入在 registers 里面的。
__global__ void MatrixMulKernel(float* d_M, float* d_N, float* d_P, int Width)
{
// Calculate the row index of the Pd element and M
int Row = blockIdx.y*TILE_WIDTH + threadIdx.y;
// Calculate the column index of Pd and N
int Col = blockIdx.x*TILE_WIDTH + threadIdx.x;
float Pvalue = 0;
// each thread computes one element of the block sub-matrix
for (int k = 0; k < Width; ++k)
Pvalue += d_M[Row*Width+k]* d_N[k*Width+Col];
d_P[Row*Width+Col] = Pvalue;// 相当于之访问一次内存,写入一次。
}
__global__ void MatrixMulKernel(float* d_M, float* d_N, float* d_P, int Width)
{
__shared__float Mds[TILE_WIDTH][TILE_WIDTH];
__shared__float Nds[TILE_WIDTH][TILE_WIDTH];
int bx = blockIdx.x; int by = blockIdx.y;
int tx = threadIdx.x; int ty = threadIdx.y;
// Identify the row and column of the d_P element to work on
int Row = by * TILE_WIDTH + ty;
int Col = bx * TILE_WIDTH + tx;
float Pvalue = 0;
// Loop over the d_M and d_N tiles required to compute the d_P element
for (int m = 0; m < Width/TILE_WIDTH; ++m)
{
// Collaborative loading of d_M and d_N tiles into shared memory
Mds[tx][ty] = d_M[Row*Width + m*TILE_WIDTH+tx];
Nds[tx][ty] = d_N[(m*TILE_WIDTH+ty)*Width + Col];//colaescing
__syncthreads();
for (int k = 0; k < TILE_WIDTH; ++k)
{
Pvalue += Mds[tx][k] * Nds[k][ty];// shared memory 一级缓存,并不需要
}
__synchthreads();
}
d_P[Row*Width+Col] = Pvalue;
}
CUDA Prefix Sum (Scan)

CPU: O(N-1)
void scan( float* scanned, float* input, int length)
{
scanned[0] = 0;
for(int i = 1; i < length; ++i)
{
scanned[i] = scanned[i-1] + input[i-1];
}
}
Parallel: Hillis & Steele O(log(N))
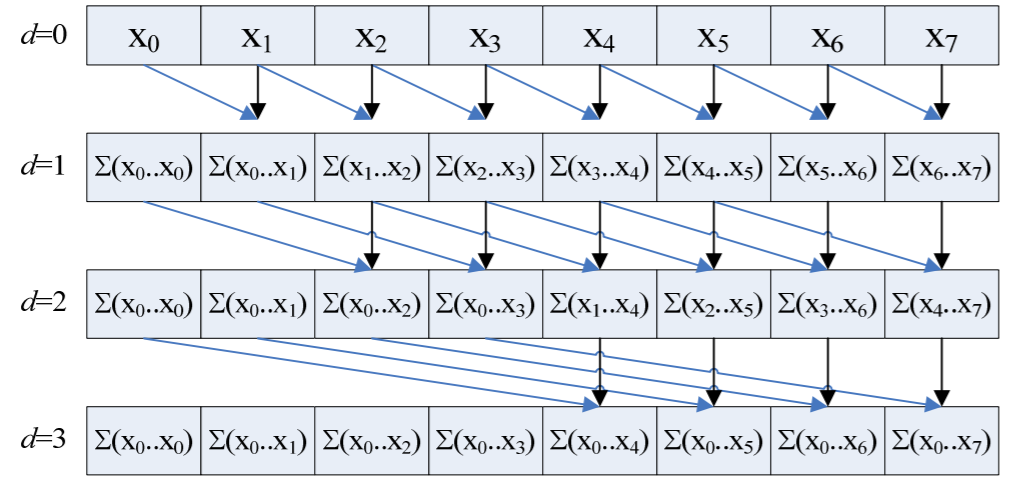

__global__ void scan(float *g_odata, float *g_idata, int n)
{
extern __shared__ float temp[]; // allocated on invocation
int thid = threadIdx.x;
int pout = 0, pin = 1;
// load input into shared memory.
// Exclusive scan: shift right by one and set first element to 0
temp[thid] = (thid > 0) ? g_idata[thid-1] : 0;
__syncthreads();
for( int offset = 1; offset < n; offset <<= 1 )
{
pout = 1 - pout; // swap double buffer indices
pin = 1 - pout;
if (thid >= offset)
temp[pout*n+thid] += temp[pin*n+thid - offset];
else
temp[pout*n+thid] = temp[pin*n+thid];
__syncthreads();
}
g_odata[thid] = temp[pout*n+thid1]; // write output
}
Balanced Trees: O(logN)
add operations O(NlogN), inefficient



__global__ void prescan(float *g_odata, float *g_idata, int n)
{
extern __shared__ float temp[];// allocated on ocation
int thid = threadIdx.x;
int offset = 1;
temp[2*thid] = g_idata[2*thid]; // load input into red memory
temp[2*thid+1] = g_idata[2*thid+1];
for (int d = n>>1; d > 0; d >>= 1) // build sum in ce up the tree
{
__syncthreads();
if (thid < d)
{
int ai = offset*(2*thid+1)-1;
int bi = offset*(2*thid+2)-1;
temp[bi] += temp[ai];
}
offset *= 2;
}
if (thid == 0) { temp[n - 1] = 0; } // clear the last ment
for (int d = 1; d < n; d *= 2) // traverse down tree & ld scan
{
offset >>= 1;
__syncthreads();
if (thid < d)
{
int ai = offset*(2*thid+1)-1;
int bi = offset*(2*thid+2)-1;
float t = temp[ai];
temp[ai] = temp[bi];
temp[bi] += t;
}
}
__syncthreads();
g_odata[2*thid] = temp[2*thid]; // write results to ice memory
g_odata[2*thid+1] = temp[2*thid+1];
}
Avoid shared memory bank conflicts
add operations O(N), work-efficient
add padding every 16 element

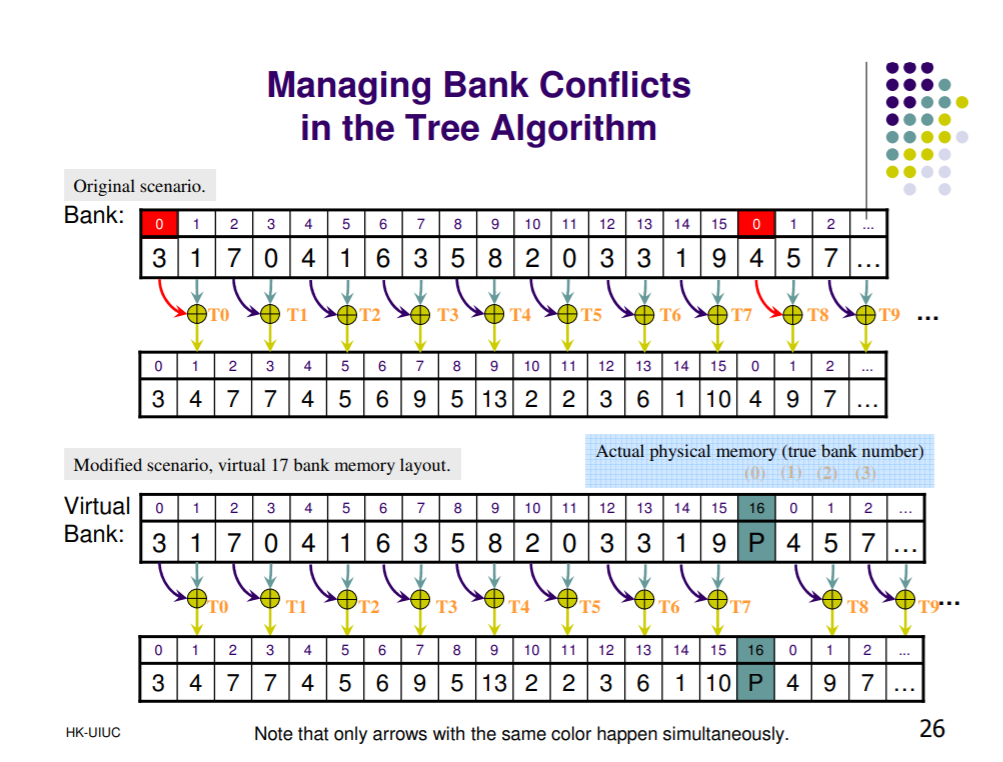
Atomic Operation
An atomic function performs a read-modify-write atomic operation on one 32-bit or 64-bit word residing in global or shared memory.
return old value!!
atomicAdd()
int atomicAdd(int* address, int val);
unsigned int atomicAdd(unsigned int* address,
unsigned int val);
unsigned long long int atomicAdd(unsigned long long int* address,
unsigned long long int val);
float atomicAdd(float* address, float val);
double atomicAdd(double* address, double val);
atomicSub()
int atomicSub(int* address, int val);
unsigned int atomicSub(unsigned int* address,
unsigned int val);
atomicExch()
int atomicExch(int* address, int val);
unsigned int atomicExch(unsigned int* address,
unsigned int val);
unsigned long long int atomicExch(unsigned long long int* address,
unsigned long long int val);
float atomicExch(float* address, float val);
atomicMin() or atomicMax()
int atomicMin(int* address, int val);
unsigned int atomicMin(unsigned int* address,
unsigned int val);
unsigned long long int atomicMin(unsigned long long int* address,
unsigned long long int val);
atomicInc()
reads the 32-bit word old located at the address address in global or shared memory, computes ((old >= val) ? 0 : (old+1)), and stores the result back to memory at the same address
unsigned int atomicInc(unsigned int* address,
unsigned int val);
atomicDec()
unsigned int atomicDec(unsigned int* address,
unsigned int val);
reads the 32-bit word old located at the address address in global or shared memory, computes (((old == 0) || (old > val)) ? val : (old-1) ), and stores the result back to memory at the same address.
atomicACS()
(old == compare ? val : old)
int atomicCAS(int* address, int compare, int val);
unsigned int atomicCAS(unsigned int* address,
unsigned int compare,
unsigned int val);
atomicAnd(), atomicOr(), atomicXor()
| **old & val, old | val, old ^ val;** |