Parallel Computing - Machine Learning
Parallel 减少的是Wall-time, CPU,GPU运行的时间时不变的,对并行来说
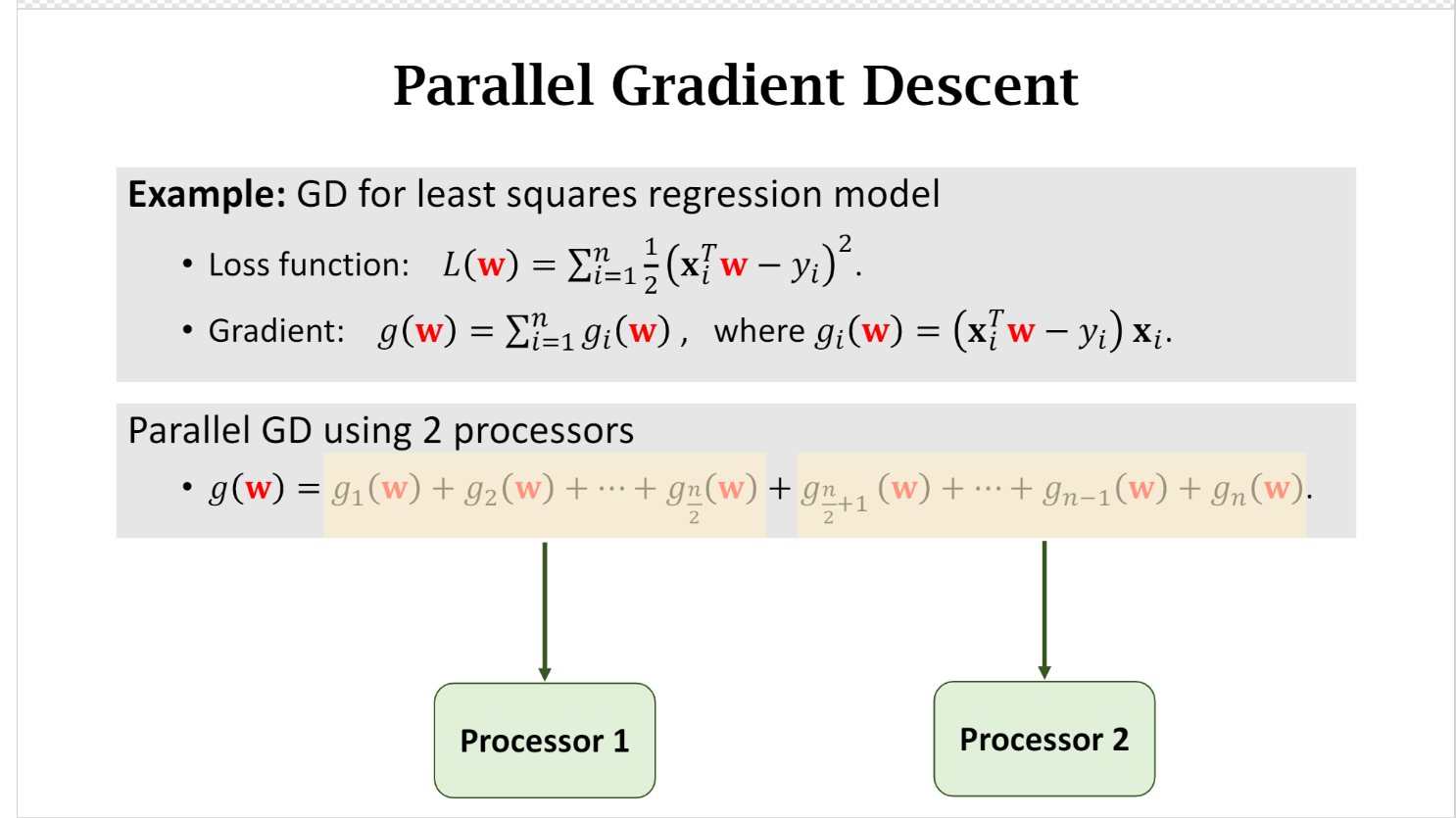
Gradient Descent:

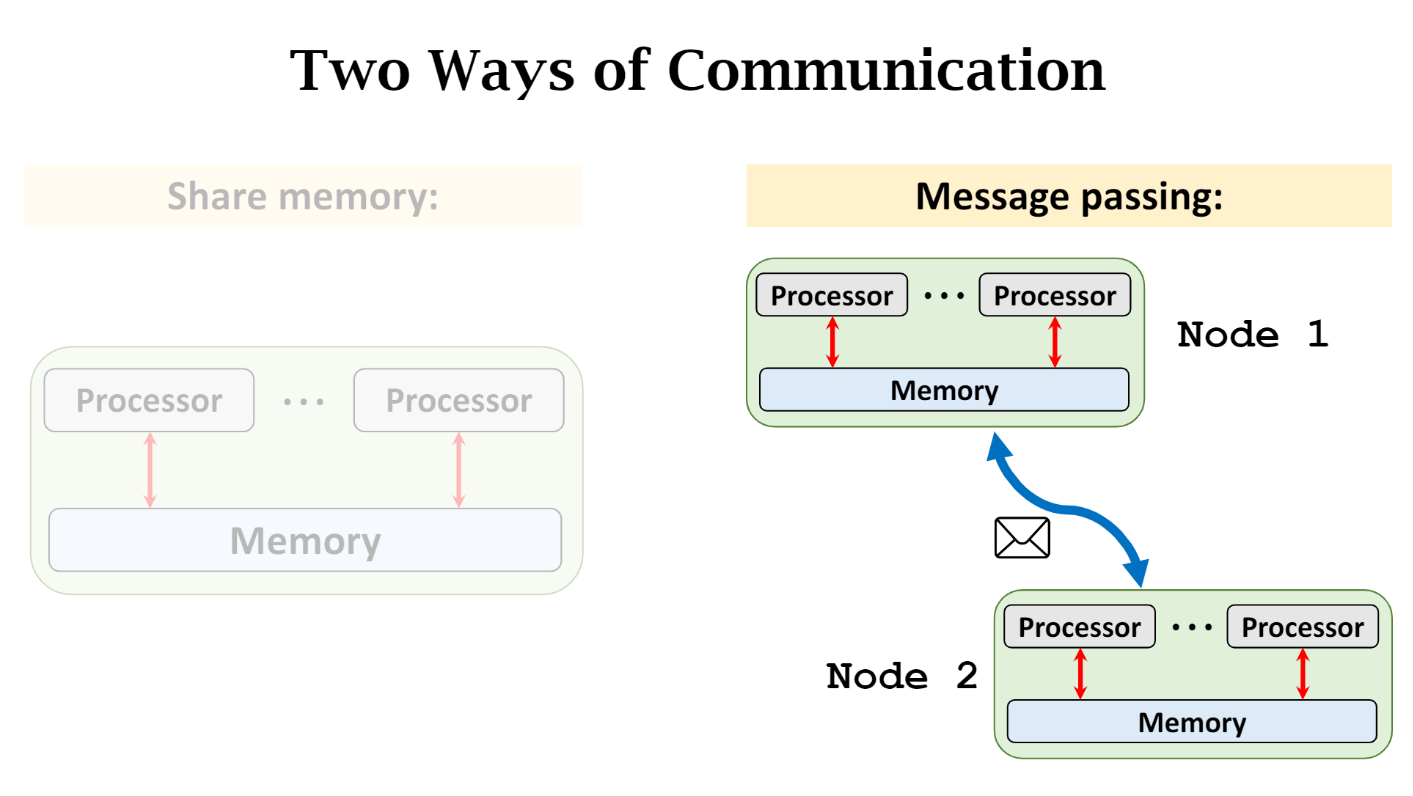
Communication
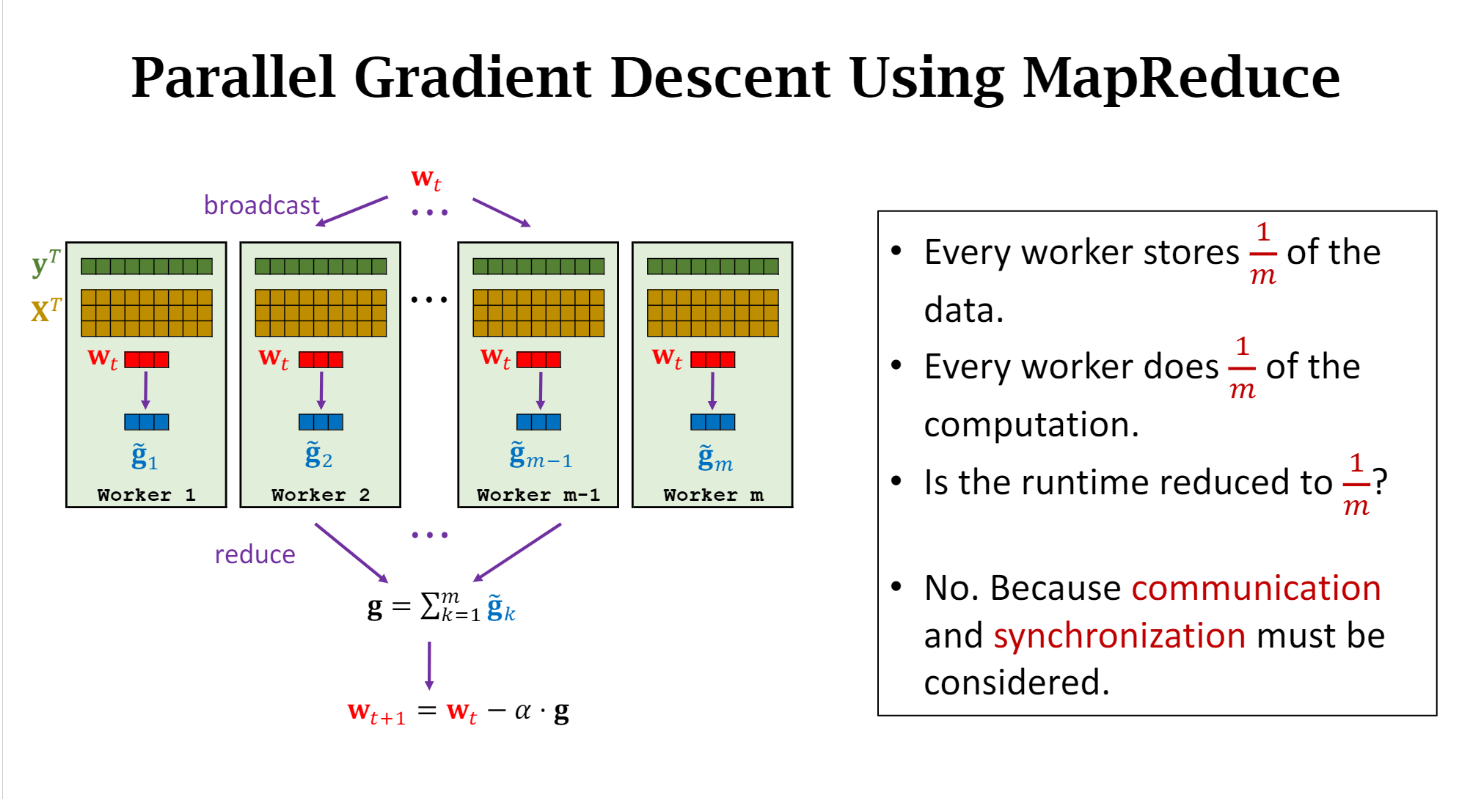
MapReduce
Synchronization after each map, or reduce
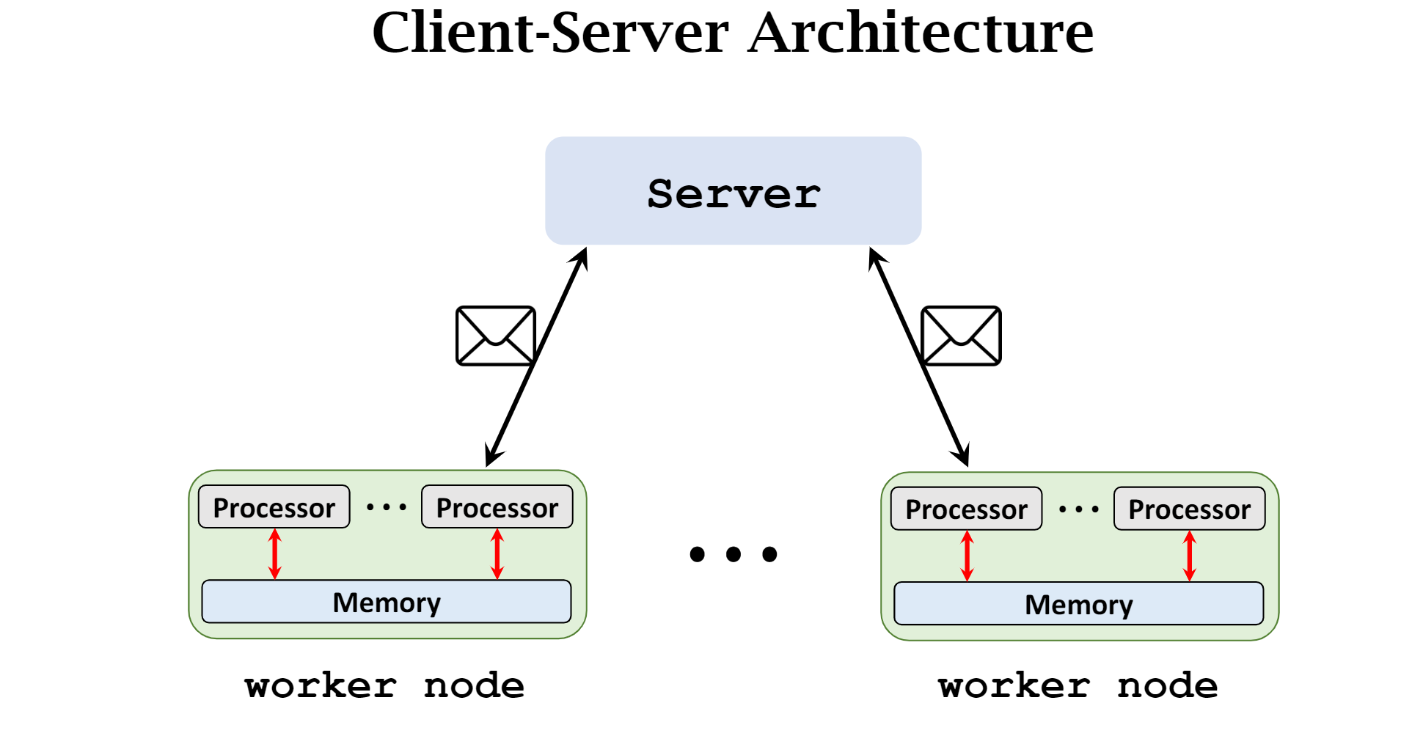
client-server, message-passing communication, and synchronous
MapReduce 是 同步的!!!
加速比
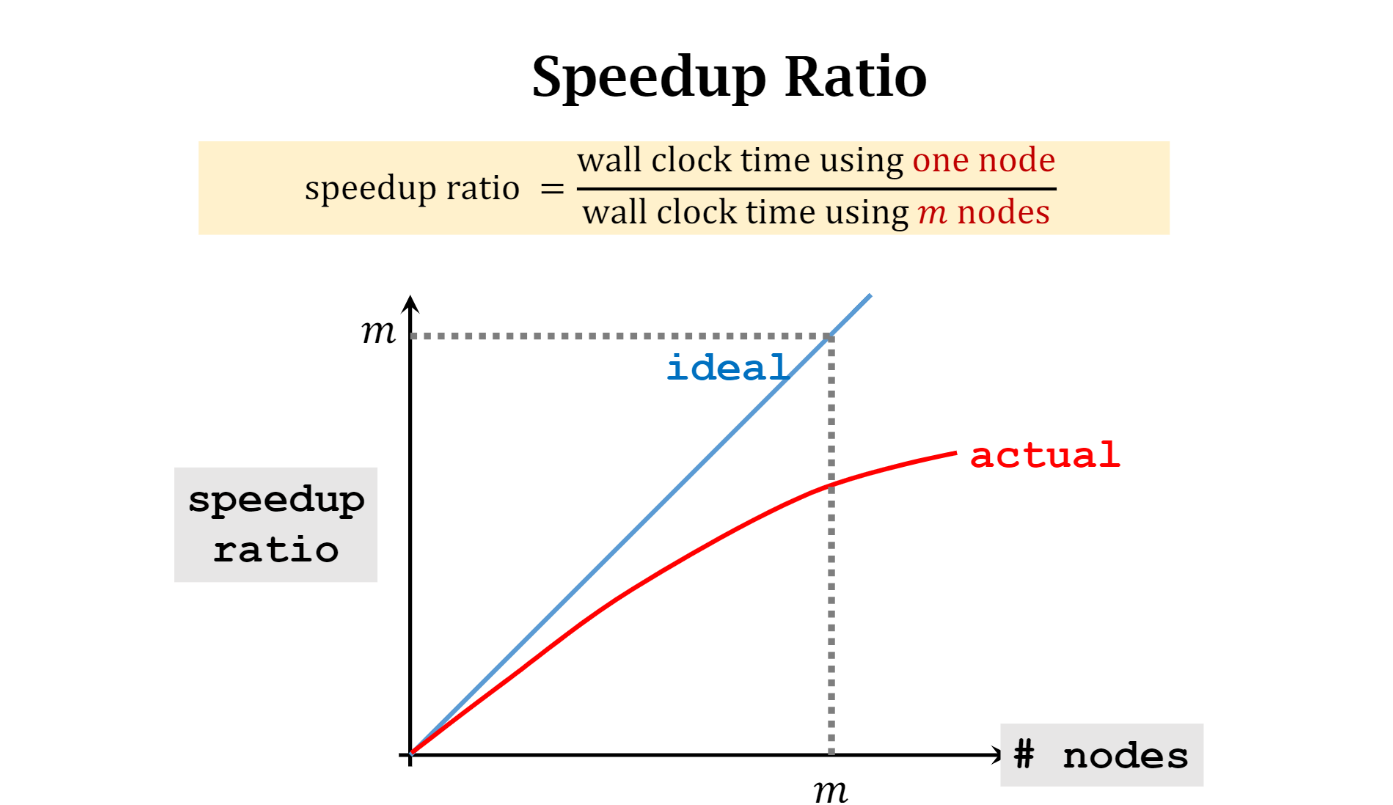
需要考虑 synchronization and communication

通信复杂度:server 和 worker之间传输数据量。正比于参数,work nodes越多,复杂度也就越高
延迟:1bit和一个矩阵延迟几乎都是一样的 是。是由computer network 决定的 通信次数越多,latency造成的代价也就越大
更通用的公式 latency + communication complexity/bandwidth + communication complexity*C(每个字节需要计算的时间)
同步 synchronization: worker 有快有慢。。
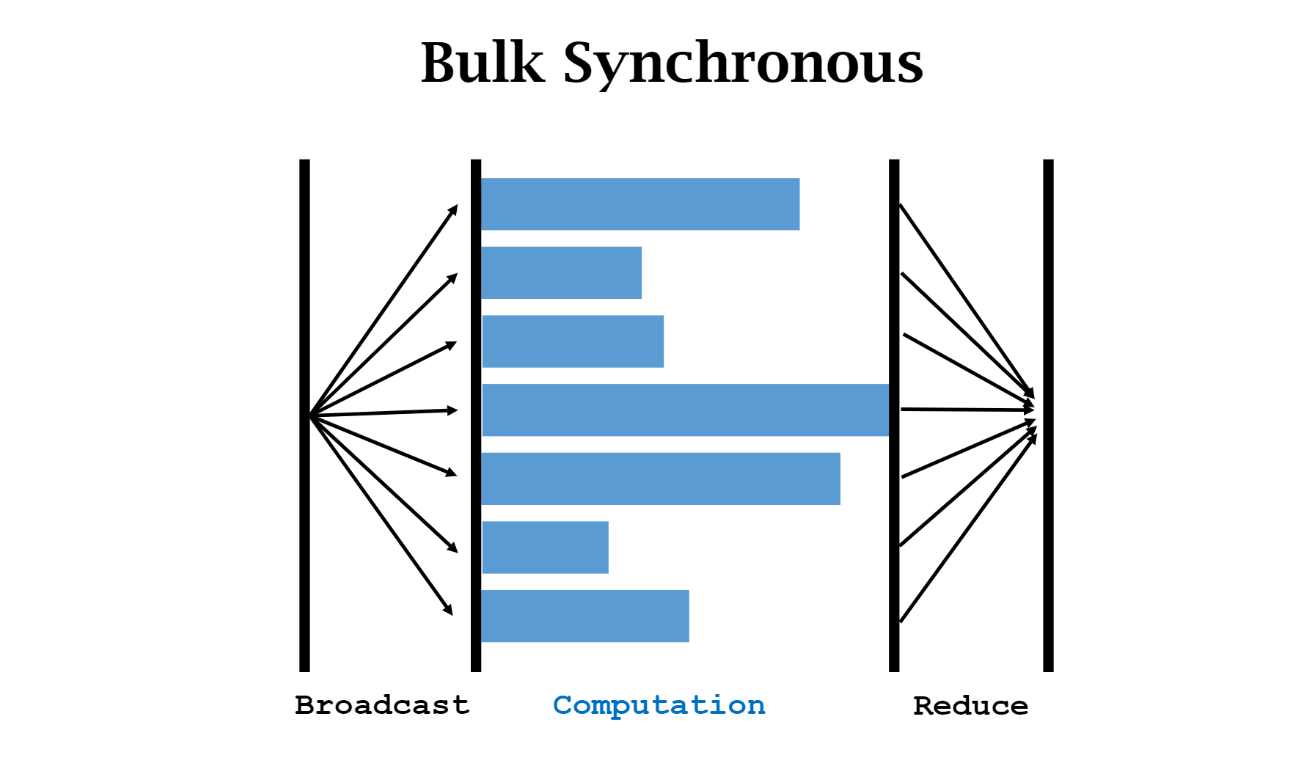
异步 gradient descent
每个worker比较稳定。
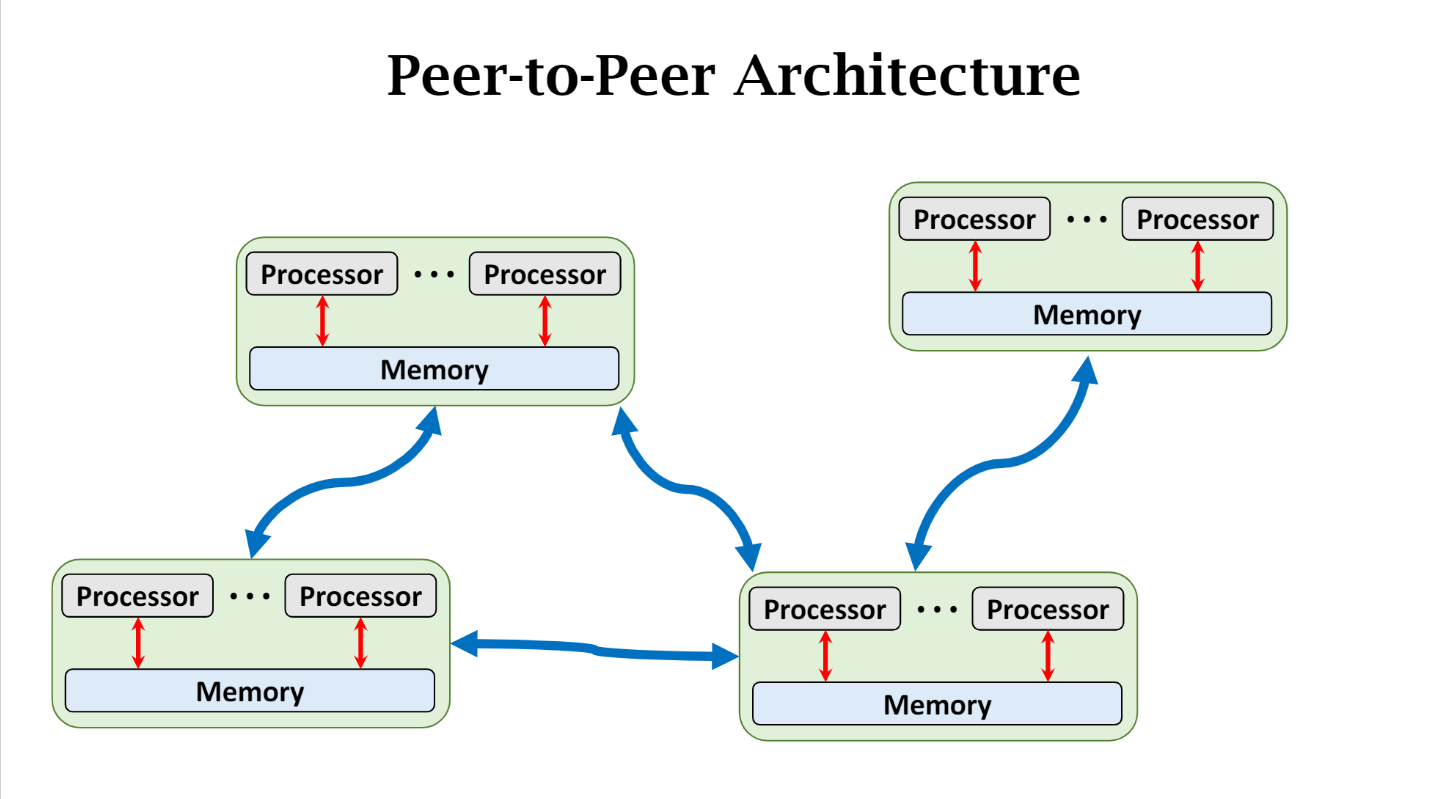
Decentralized Network
peer-to-peer, message-passing-communication


Allreduce 算法

Reduce + BroadCast (MPI)
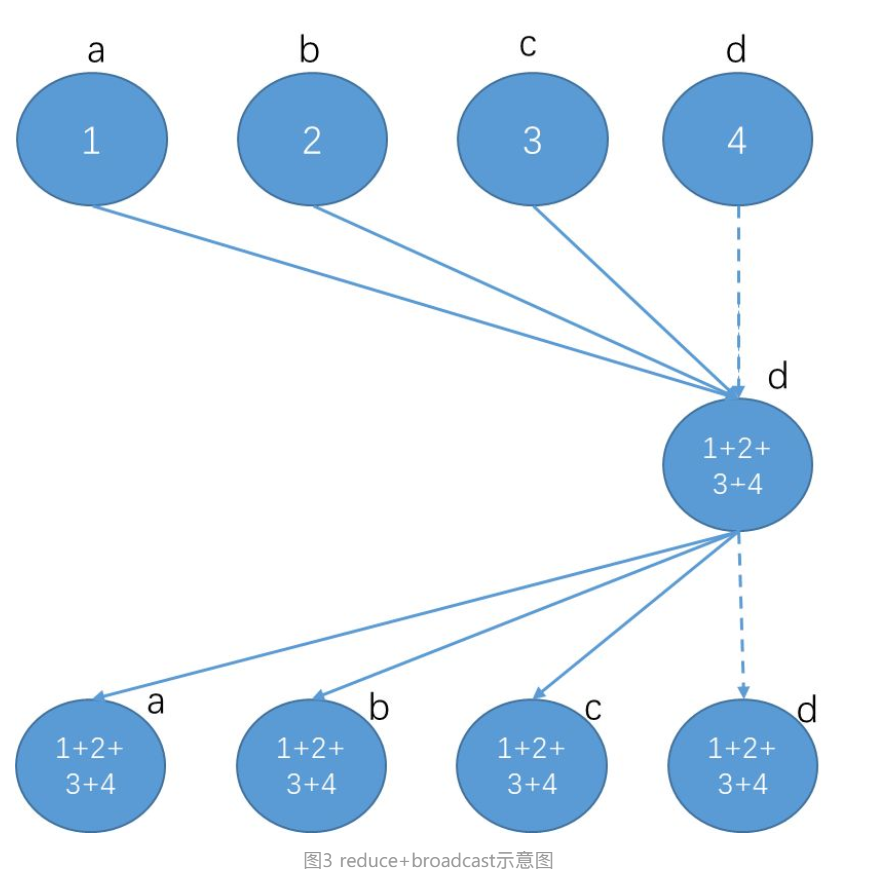
2*(α + S/B) + N*S*C
在parameter server节点上的计算耗时是N*S*C
该算法最大的缺点就是parameter server节点的带宽会成为瓶颈
Tree: recursive halving and doubling
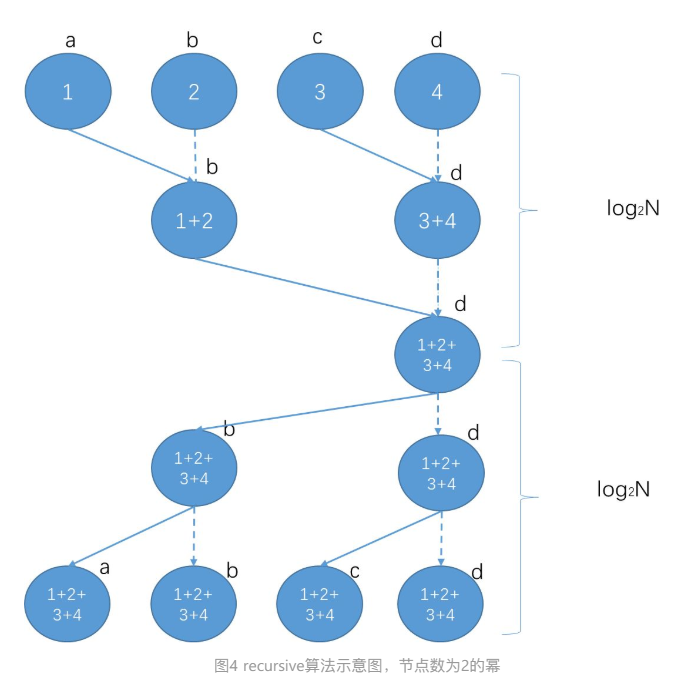
相比reduce+broadcast,最大的改进是规避了单节点的带宽瓶颈。
在halving和doubling的每一步,通信耗时都是α + S/B,计算耗时都是S*C。
步数约等于log2N,因此整体耗时是2*log2N*(α + S/B + S*C )。
ButterFly
Recursive算法中一个明显的不足是,在halving阶段有一半的节点没有进行send发送操作,只是“傻傻”等待接收数据。比如图4中的第一步,a->b,c->d发送数据的时候,b和d节点的发送带宽没有被利用起来。
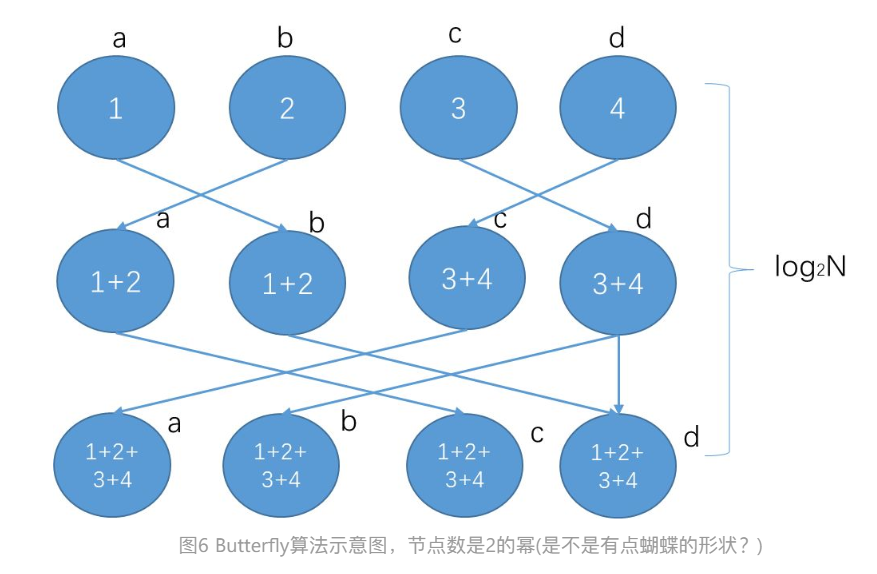
整体耗时大概是log2N(α + S/B + SC )
核心概念:让所有node 的 send 和 recv 带宽都利用起来,这样达到最快的速度。
Ring AllReduce
Butterfly已经在每步中把每个节点的send/recv带宽都利用起来了,那是不是完美无缺了?答案是否定的。其潜在的问题是如果数据块过大(S过大),每次都完整send/recv一个S的数据块,并不容易把带宽跑满,且容易出现延时抖动。。
Ring算法默认把每个节点的数据切分成N份。当然,这要求数据块中的元素个数count =S/sizeof(element)大于N,否则要退化为使用其他算法。
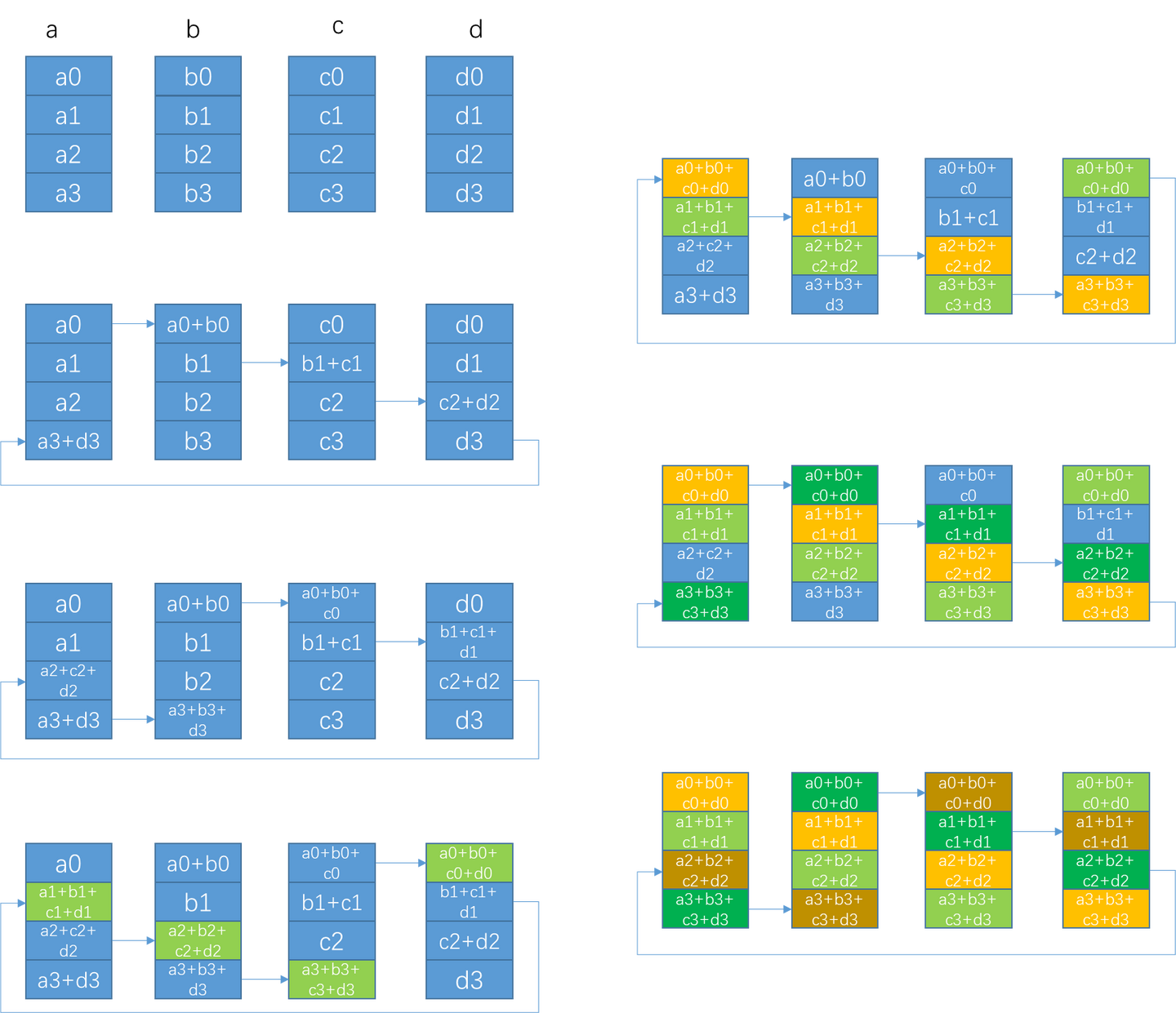
第一阶段通过(N-1)步,让每个节点都得到1/N的完整数据块。每一步的通信耗时是α+S/(NB),计算耗时是(S/N)*C。 这一阶段也可视为scatter-reduce。
第二阶段通过(N-1)步,让所有节点的每个1/N数据块都变得完整。每一步的通信耗时也是α+S/(NB),没有计算。这一阶段也可视为allgather。
整体耗时大概是2(N-1)[α+S/(NB)] + (N-1)[(S/N)C]
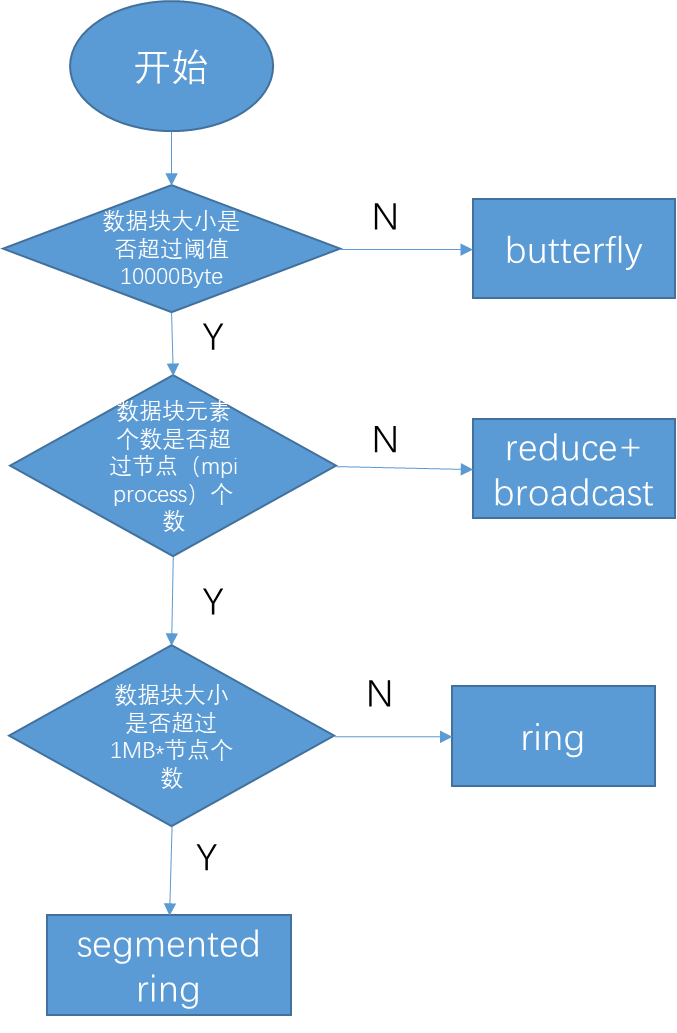
ALlReduce Algorithms Choosing
CPU cache 对程序的影响 (Matrix)
/*square1.cpp*/
/*未经优化的矩阵乘法程序-不高效*/
#include
using namespace std;
#define N 1000
int a[N][N] = {0}, b[N][N] = {0}, c[N][N] = {0};
int main() {
int i, j, k;
for (i = 0; i < N; i++) {
for (j = 0; j < N; j++) {
a[i][j] = i+j;
b[i][j] = i+j;
}
}
for (i = 0; i < N; i++) {
for (j = 0; j < N; j++) {
for (k = 0; k < N; k++) {
c[i][j] += a[i][k] * b[k][j];
}
}
}
}
/*square2.cpp*/
/*优化过的矩阵乘法程序*/
#include
using namespace std;
#define N 1000
int a[N][N] = {0}, b[N][N] = {0}, c[N][N] = {0};
int main() {
int i, j, k;
for (i = 0; i < N; i++) {
for (j = 0; j < N; j++) {
a[i][j] = i+j;
b[i][j] = i+j;
}
}
for (i = 0; i < N; i++) {
for (k = 0; k < N; k++) { // 先固定k
for (j = 0; j < N; j++) {
c[i][j] += a[i][k] * b[k][j];
}
}
}
}
square1.cpp中因为第三层循环(最内层循环)是对k进行循环,因此b[k][j]是对b逐列进行访问。我们知道内存中二维数组是以行为单位连续存储的,逐列访问将会每次跳1000*4(bytes)。根据cpu cache的替换策略,将会有大量的cache失效。
因此square2.cpp将j循环和k循环交换位置,这样就保证了
c[i][j] += a[i][k] * b[k][j];
这条语句中k和i是固定的,这样对j的访问就是某一行的, 对内存的访问是连续的,增加了cache的命中率,大大提升了程序执行速度。
平时写程序时,也应当尽量使cpu对内存的访问,是尽可能连续的。
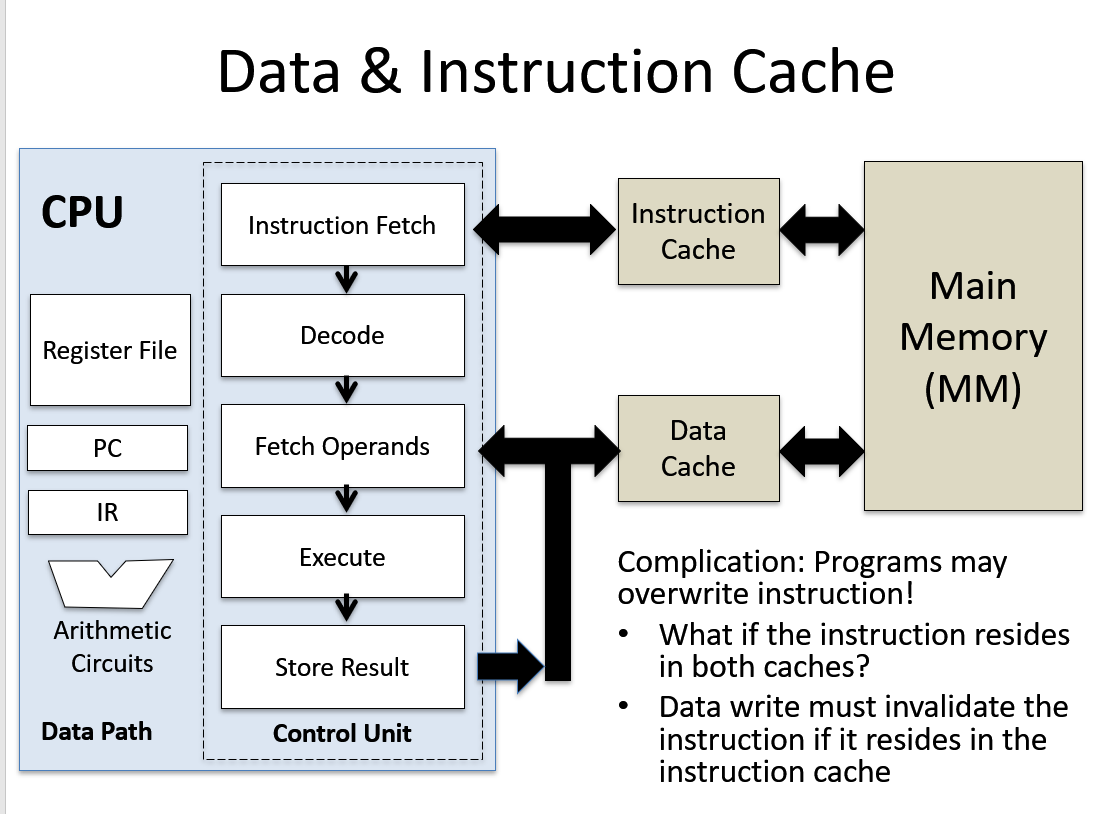
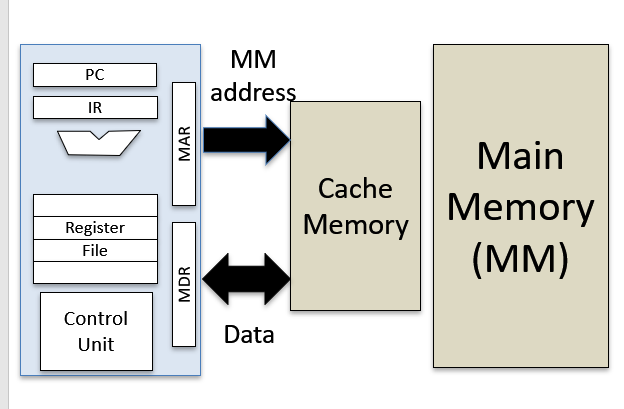
PC IR
PC: program counter –> points to next instruction address 用来指出下一条指令在主存储器中的地址。
IR: instruction register 当执行一条指令时,首先把该指令从主存读取到数据寄存器中,然后再传送至指令寄存器。
地址寄存器(Address Register,AR)用来保存CPU当前所访问的主存单元的地址。
累加寄存器通常简称累加器(Accumulator,AC),是一个通用寄存器。为ALU提供一个工作区,可以为ALU暂时保存一个操作数或运算结果。
Condition Codes: s a collection of status flag bits for a processor. Zero Flag: Indicates that the result of an arithmetic or logical operation (or, sometimes, a load) was zero.
C: CPSR的第29位是C,进位标志位。一般情况下,进行无符号数的运算。 加法运算:当运算结果产生了进位时(无符号数溢出),C=1,否则C=0。 减法运算(包括CMP):当运算时产生了借位时(无符号数溢出),C=0,否则C=1
我们知道,当两个数据相加的时候,有可能产生从最高有效位向更高位的进位。由于这个进位值在32位中无法保存,我们就只是简单的说这个进位值丢失了。其实CPU在运算的时候,并不丢弃这个进位制,而是记录在一个特殊的寄存器的某一位上。ARM下就用C位来记录这个进位值
V: overflow 正数 + 正数 为负数 溢出 负数 + 负数 为正数 溢出 正数 + 负数 不可能溢出
Cache: Introduction

Cache holds fixed sized blocks(e.g., 64 bytes)
当没有在cache中找到的时候,就从memory读入到cache,这时候cache需要make room, delete other data (LRU, least recently used)
Cache 有用的原因,即使很小 256 KB
Locality of Reference:
-
Spatial Locality: If a memory address is referenced, chances are good a location near that one will be referenced soon
-
Temporal locality: If a memory location is referenced now, chances are good it will be referenced again soon in the near future
Things that tend to yield poor locality
Large arrays where elements accessed “randomly” Large dynamically allocated data structures (malloc) Excessive use of function calls (e.g., system calls)
Content Addressable Memory (hashing)
key-value
key: MM address; Data: contents M[A]
Cache: 16 bits address + 16 bits Data
HashFunction: map a memory address to a cache memory address
one Block: 16 bits = one word
Direct Mapped Cache: one to one Fully Associative Cache: ont to all K-way Set Associate Cache: one to k possible locations in the cache
associativity 提高,missing更少,但是访问速度减慢,因为可能存在多个位置,这是个balancing的问题。一般使用 1, 2, 4, 8
Replacement Policy
Cache Block: atomic unit of data stored in cache
LC-3 example: block = 1 word = 2 bytes
LRU replacement
Least Recently Used Special Case: 2 Way set associative
- LRU implement by remembering the most recently used (MRU) block (1 bit)
虚拟内存 virtual memory
use main memory as a “cache” for storage on disk
each “block” is called a ‘page’ (4KB or 8 KB typical)
In principle, programs that use more memory than the amount of physical main memory on the machine!!
Virtual memory used to keep programs executing on the same machine from interfering with each other
虚拟内存不只是“用磁盘空间来扩展物理内存”的意思——这只是扩充内存级别以使其包含硬盘驱动器而已。把内存扩展到磁盘只是使用虚拟内存技术的一个结果,它的作用也可以通过覆盖或者把处于不活动状态的程序以及它们的数据全部交换到磁盘上等方式来实现
虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换.
虚拟内存将主存看成是一个磁盘的高速缓存,主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据。
从概念上来说,虚拟内存被组织成为一个由存放在磁盘上的 N 个连续的字节大小的单元组成的数组,也就是字节数组。每个字节都有一个唯一的虚拟地址作为数组的索引


虚拟内存可以用来:
- 隔离开不同程序,防止修改到其他程序
- 程序运行地址不确定,不同次加载位置不确定
- 内存使用率低下
分页这个技术仍然是一种虚拟地址空间到物理地址空间映射的机制。但是,粒度更加的小了。单位不是整个程序,而是某个“页”,一段虚拟地址空间组成的某一页映射到一段物理地址空间组成的某一页。
正是因为有了分页的概念,程序的换入换出就可以以页为单位了。那么,为什么就可以只换出某一页呢?实际上,不是为什么可以换出某一页,而是可以换出CPU还用不到的那些程序代码、数据。但是,把这些都换出到磁盘,万一下次CPU就要使用这些代码和数据怎么办?又得把这些代码、数据装载进内存。性能有影响对吧。所以,我们把换入换出的单位变小,变成了“页” 这样对性能影响减少。
总结:分页好处
- 分页是为了解决RAM利用率不高的问题。有了分页,就可以把RAM看成Disk的Cache,LRU的代码(页)就可以加载到disk上,从而可以在RAM上执行更经常的页
- 为了不影响性能,把页变小,这样就可以每次加载一小部分。
Cache Read
If the processor finds that the memory location is in the cache, a cache hit has occurred. However, if the processor does not find the memory location in the cache, a cache miss has occurred. In the case of a cache hit, the processor immediately reads or writes the data in the cache line. For a cache miss, the cache allocates a new entry and copies data from main memory, then the request is fulfilled from the contents of the cache.
Multiprocessor (Uniform Memory Access Architecture)
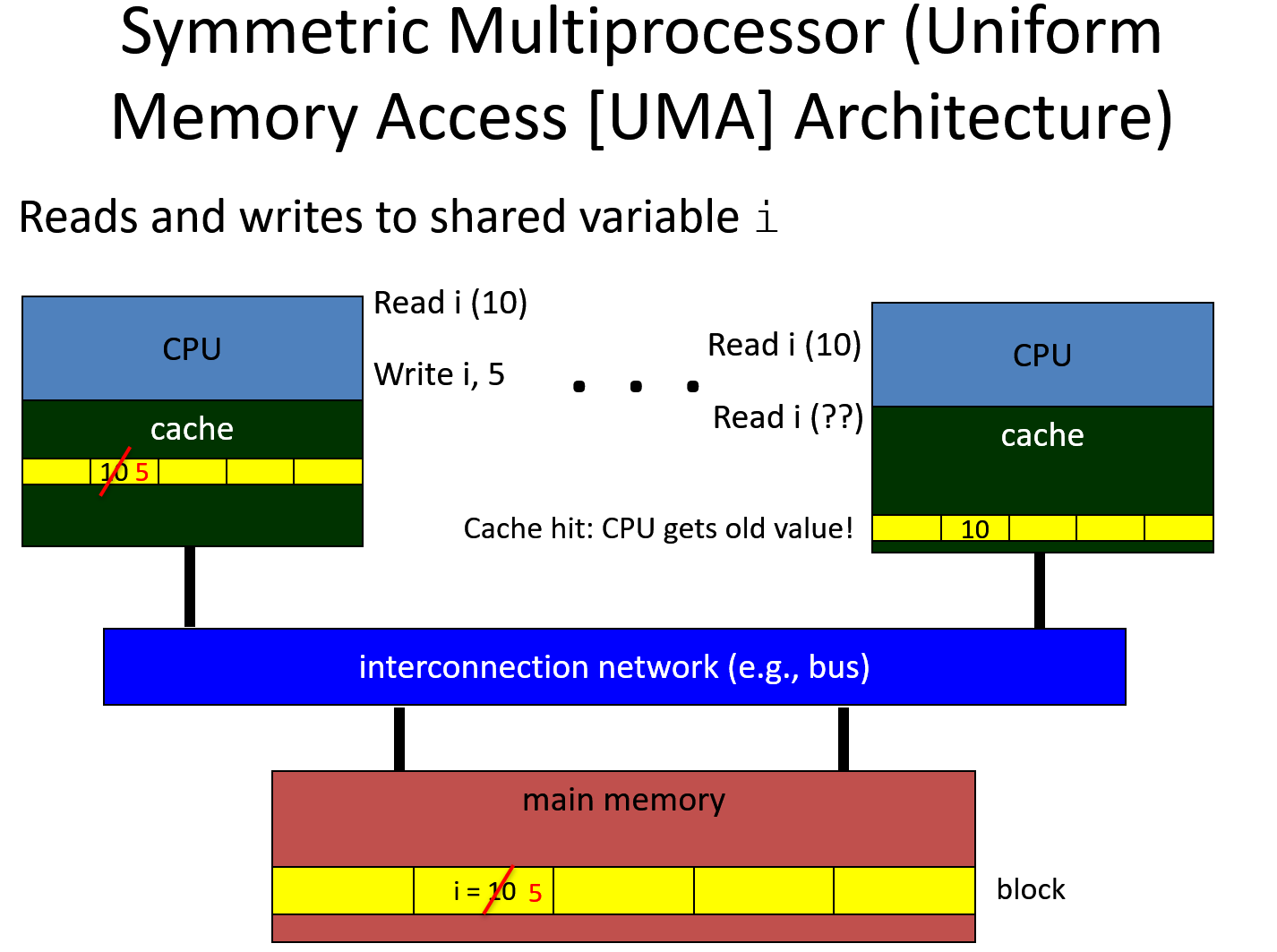
Cache Coherence
-
Write Invalidate: on write, delete the block in other caches holding that block of memory; 即使只修改了一部分,整个block还是会被delete.十分的不高效
-
Write update: on write, update other caches that hold that block of memory
How to know which has a copy
-
broadcast cache operations (bus) Bus-based systems: monitor operations on the global bus
-
Directory-based system Directory indicates which other caches hold a copy
False Sharing
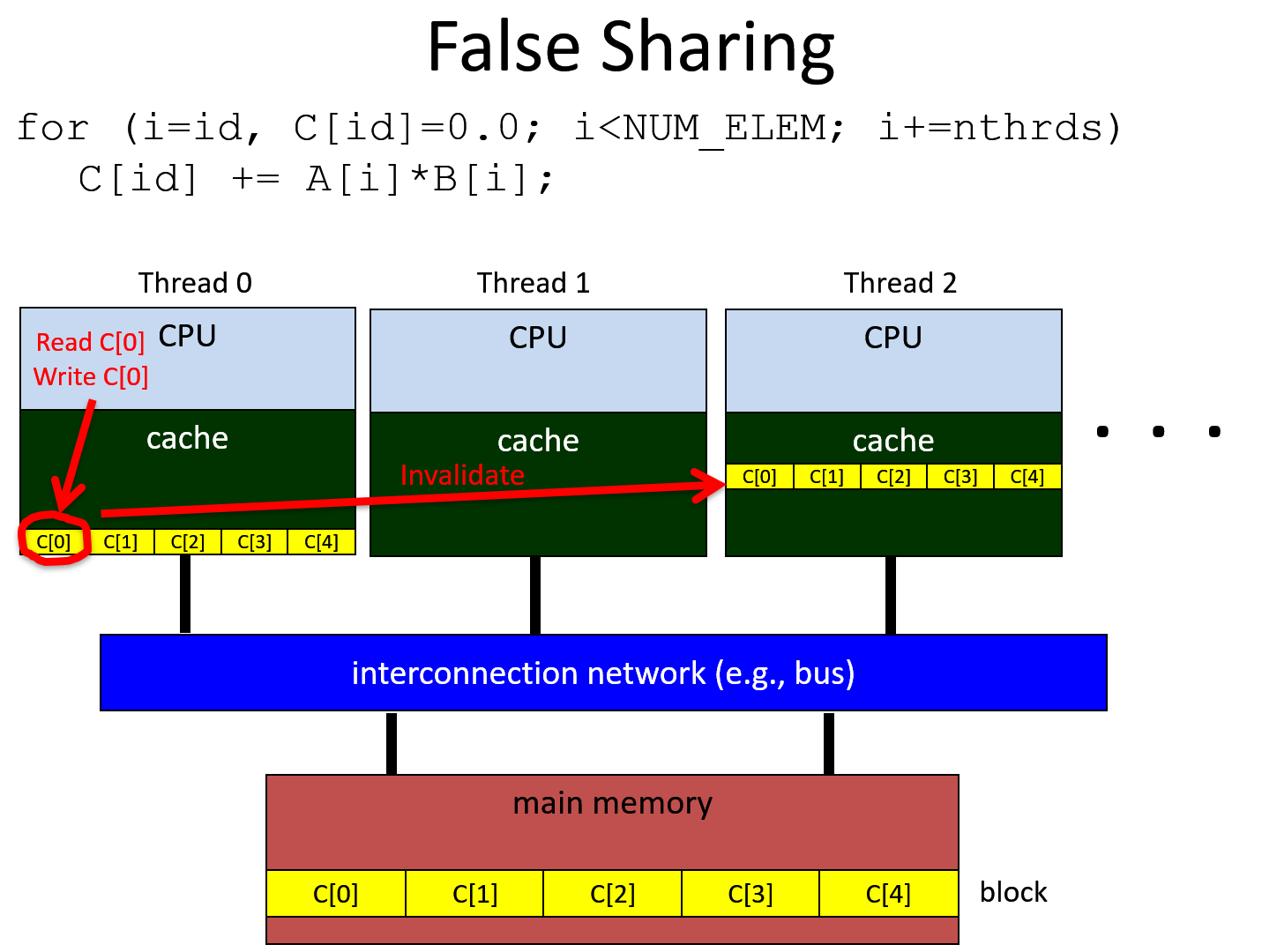
Each Read/Write sequence on C[i] will results in a cache miss and an invalidation operation, resulting in performance
different shared variable map to the same block.–> false sharing
同一个block里面variable的访问是没有区别的。writeInvalidate 肯定是不能用的。update的方法不高效,因为要copy。
要保证shared variables 被不同thread访问的时候,要放在不同的block里面。
去除false sharing,用 private variable, 来替代 C[i] 共享 variable
Cache: L1, L2, L3
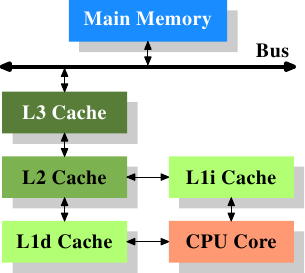
三级缓存(包括L1一级缓存、L2二级缓存、L3三级缓存)都是集成在CPU内的缓存,它们的作用都是作为CPU与主内存之间的高速数据缓冲区,L1最靠近CPU核心;L2其次;L3再次。运行速度方面:L1最快、L2次快、L3最慢;容量大小方面:L1最小、L2较大、L3最大。CPU会先在最快的L1中寻找需要的数据,找不到再去找次快的L2,还找不到再去找L3,L3都没有那就只能去内存找了
Cache 不能做的太大
太大的话访问也就变慢了,即使本身访问很快,物理方面。另外成本也很高,尤其对于CPU的一级缓存
L1 Cache
一级缓存其实还分为一级数据缓存(Data Cache,D-Cache,L1d)和一级指令缓存(Instruction Cache,I-Cache,L1i),分别用于存放数据及执行数据的指令解码,两者可同时被CPU访问,减少了CPU多核心、多线程争用缓存造成的冲突,提高了处理器的效能。
L2 Cache
L2 比 L1 慢,因为 L1物理上离CPU核心更近。而且L2容量更大。
L3 Cache 多核共享
DRAM vs SRAM
DRAM 所占硅面积大,但是速度快。
L3 is shared
Today, the L3 is characterized as a pool of fast memory common to all the CPUs on an SoC. It’s often gated independently from the rest of the CPU core and can be dynamically partitioned to balance access speed, power consumption, and storage capacity.
LRU cache O(1) implementation

Put O(1) Get O(1)
记住 Map是红黑树, Search in O(logN) unordered_map 是 hash-table, search in O(1) set也是类似的
list<pair<int,int» _lru;
// Author: Huahua
class LRUCache {
public:
LRUCache(int capacity) {
capacity_ = capacity;
}
int get(int key) {
const auto it = m_.find(key);
// If key does not exist
if (it == m_.cend()) return -1;
// Move this key to the front of the cache
cache_.splice(cache_.begin(), cache_, it->second);
return it->second->second;
}
void put(int key, int value) {
const auto it = m_.find(key);
// Key already exists
if (it != m_.cend()) {
// Update the value
it->second->second = value;
// Move this entry to the front of the cache
cache_.splice(cache_.begin(), cache_, it->second);
return;
}
// Reached the capacity, remove the oldest entry
if (cache_.size() == capacity_) {
const auto& node = cache_.back();
m_.erase(node.first);
cache_.pop_back();
}
// Insert the entry to the front of the cache and update mapping.
cache_.emplace_front(key, value);
m_[key] = cache_.begin();
}
private:
int capacity_;
list<pair<int,int>> cache_;
unordered_map<int, list<pair<int,int>>::iterator> m_;
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
## 线程和进程
进程是系统资源分配和调度的最小单位,能够单独执行一个程序。不同进程之间是独立的。进程又包括多个线程。
线程是系统指令执行的最小单位,每个线程都有自己的专有寄存器 PC,SP等,但是代码区是共享的。
CPU 上下文切换
在计算中,上下文切换是存储进程或线程状态的进程,以便可以还原它并在以后恢复执行。 这允许多个进程共享一个CPU,这是多任务操作系统的基本功能。 短语“上下文切换”的确切含义有所不同。 在多任务上下文中,它是指为一个任务存储系统状态的过程,以便可以暂停该任务并恢复另一个任务。
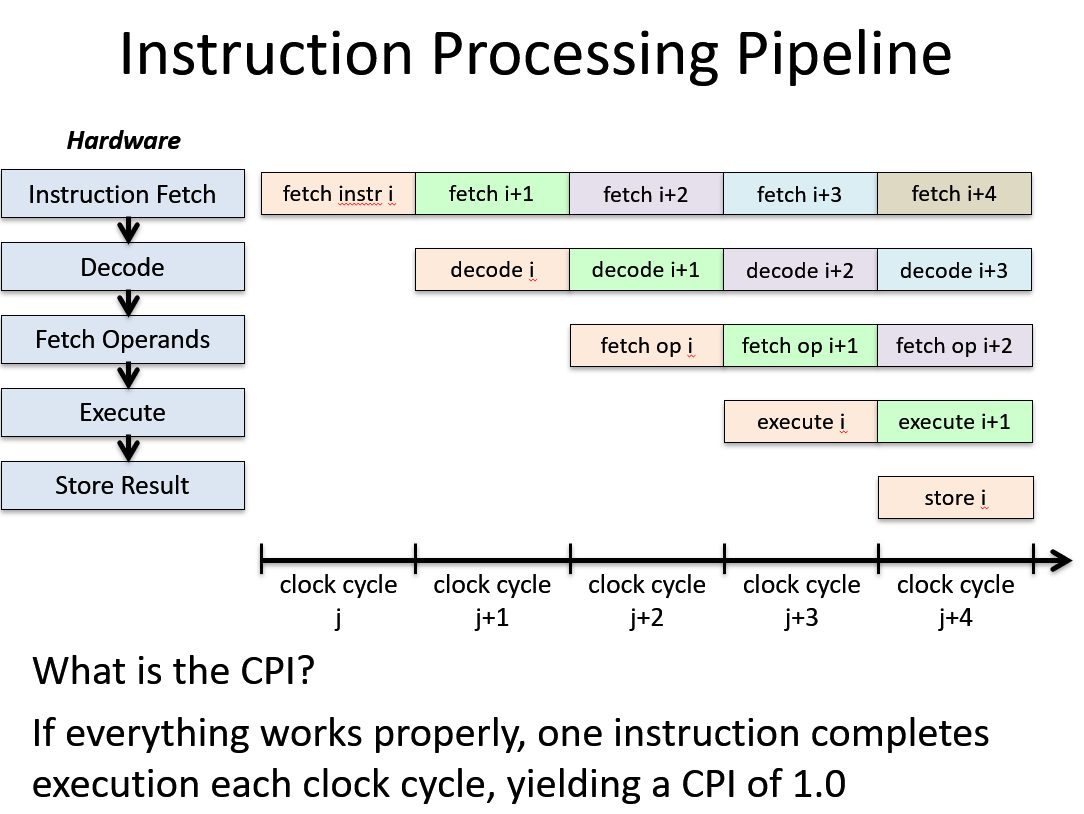
CPU pipeline
Execution time = N * CPI * cycle time
Five steps to process each instructions:
instruction fetch –> decode _–> fetch operands –> execute –> store result