CUDA - Optimization
CUDA 优化来说主要是 memory 和 compute 两方面。
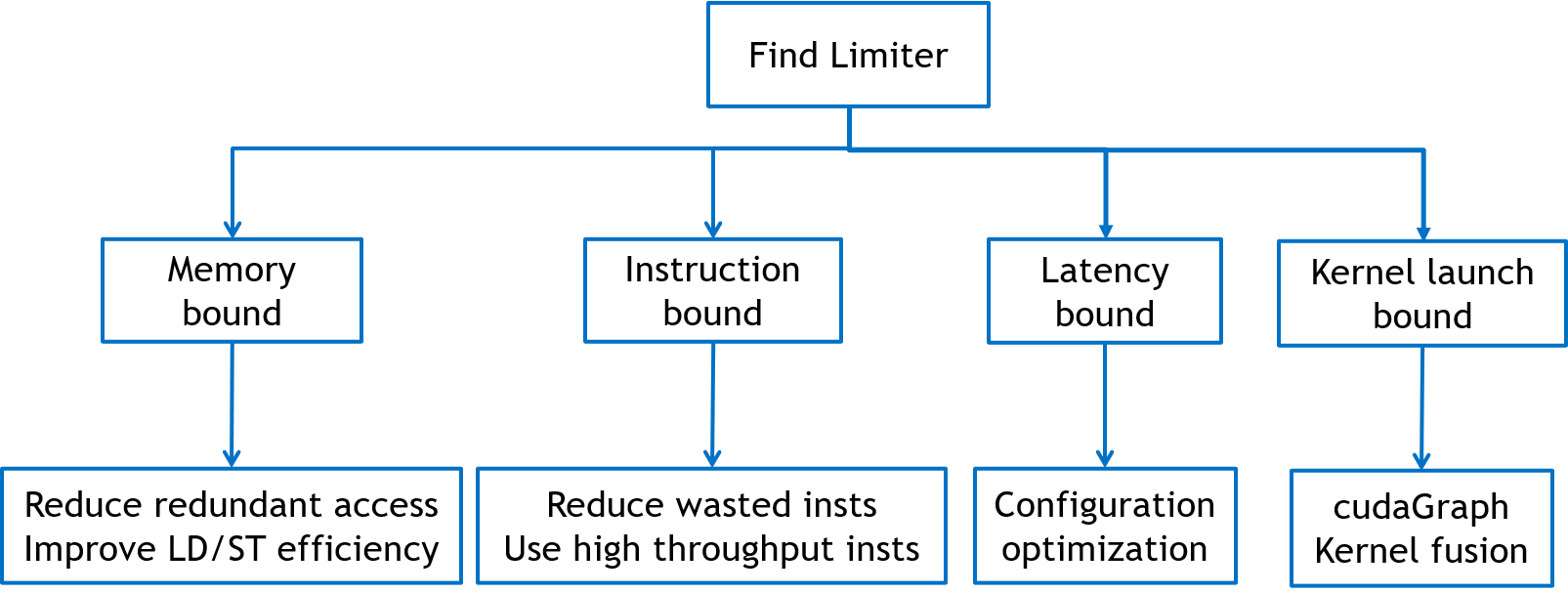
Find out the limiting factor in kernel performance
- Kernel launch bound Time(kernel launch) > Time(kernel execution)
- Memory bandwidth bound memory_utilization » SM_utilization
- Instruction throughput bound SM_utilization » memory_utilization
- Latency bound both SM_utilization and memory_utilization are low
2D Matrix Transpose
为了减少uncoalesced memory access 和 bank conflicts of shared memory, 会尽量以 row 进行 read and write,不行加入padding。正如下面方法所示。
__global__ void sharedMem(float *output, float *input, const int m,
const int n)
{
int colID_input = threadIdx.x + blockDim.x*blockIdx.x;
int rowID_input = threadIdx.y + blockDim.y*blockIdx.y;
__shared__ float sdata[32][33];// padding to avoid bank conflicts
if (rowID_input < m && colID_input < n)
{
int index_input = colID_input + rowID_input*n;
sdata[threadIdx.y][threadIdx.x] = input[index_input]; // read by row
__syncthreads();
int dst_col = threadIdx.x + blockIdx.y * blockDim.y; // write by row inside one block (block has been transposed)
int dst_row = threadIdx.y + blockIdx.x * blockDim.x;
output[dst_col + dst_row*m] = sdata[threadIdx.x][threadIdx.y]; // read shared_memmory by col (with padding, no bank conflicts)
}
}